爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
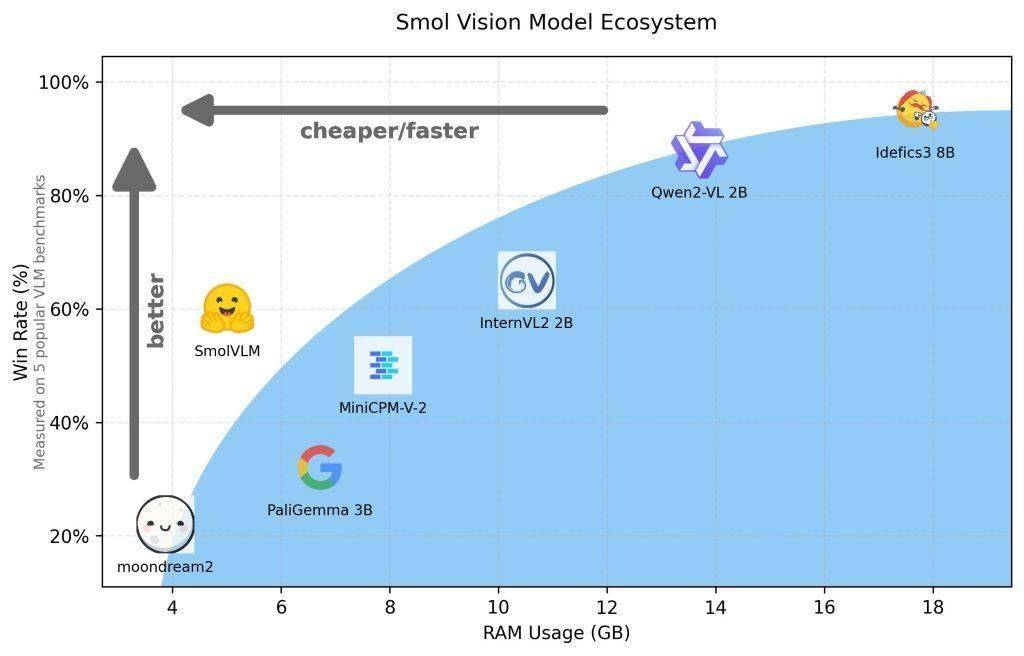
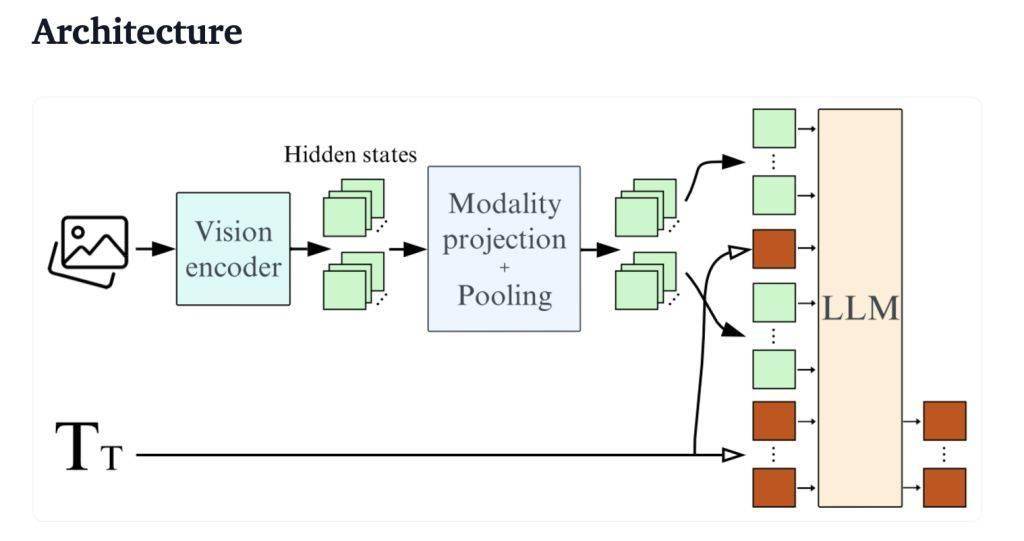
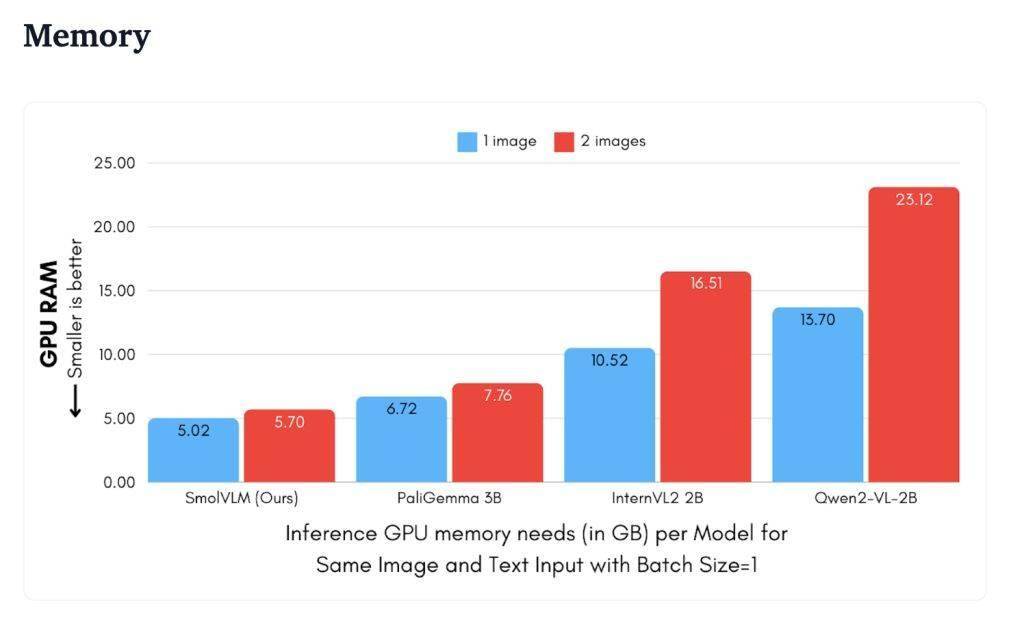
Hugging Face 平台昨日(11 月 26 日)发布博文,宣布推出 SmolVLM AI 视觉语言模型(VLM),仅有 20 亿参数,用于设备端推理,凭借其极低的内存占用在同类模型中脱颖而出。 官方表示 SmolVLM AI 模型的优点在于体积小、速度快、内存高效,并且完全开源,所有模型检查点、VLM 数据集、训练配方和工具均在 Apache 2.0 许可证下发布。 SmolVLM AI 模型共有 SmolVLM-Base(用于下游微调)、SmolVLM-Synthetic(基于合成数据微调)和 SmolVLM-Instruct(指令微调版本,可以直接用于交互式应用)三个版本。 架构 SmolVLM 最大的特点在于巧妙的架构设计,借鉴了 Idefics3,使用了 SmolLM2 1.7B 作为语言主干,通过像素混洗策略将视觉信息的压缩率提高到 9 倍。 训练数据集包括 Cauldron 和 Docmatix,并对 SmolLM2 进行了上下文扩展,使其能够处理更长的文本序列和多张图像。该模型通过优化图像编码和推理过程,有效降低了内存占用,解决了以往大型模型在普通设备上运行缓慢甚至崩溃的问题。 内存 SmolVLM 将 384x384 像素的图像块编码为 81 个 tokens,因此在相同测试图片下,SmolVLM 仅使用 1200 个 tokens,而 Qwen2-VL 则使用 1.6 万个 tokens。 吞吐量 SmolVLM 在 MMMU、MathVista、MMStar、DocVQA 和 TextVQA 等多个基准测试中表现出色,且处理速度相比较 Qwen2-VL,预填充(prefill)吞吐量快 3.3 到 4.5 倍,生成吞吐量快 7.5 到 16 倍。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2024-11-27 22:22:14
发表于 2024-11-27 22:22:14

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶