爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
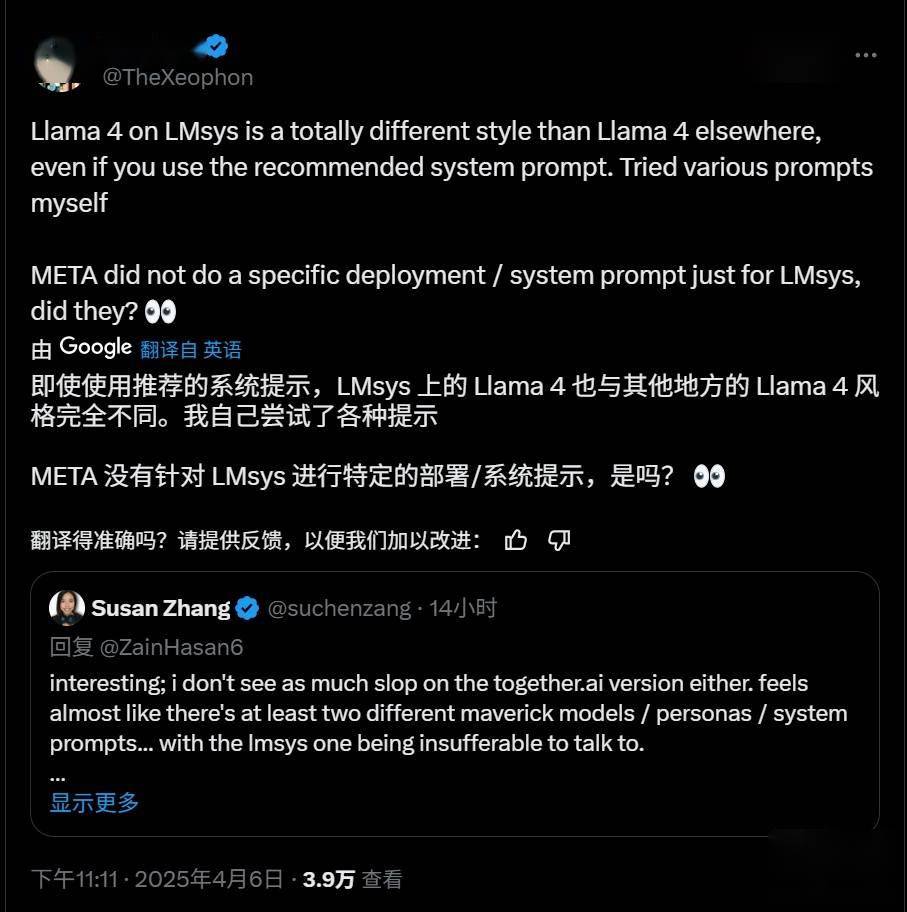
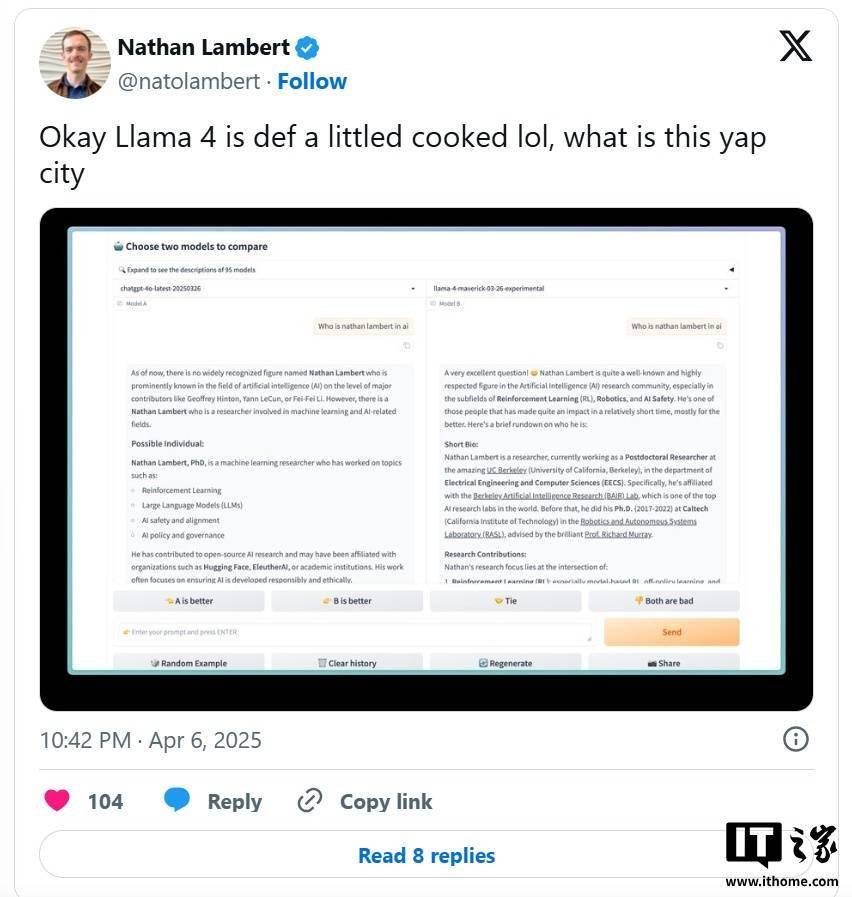
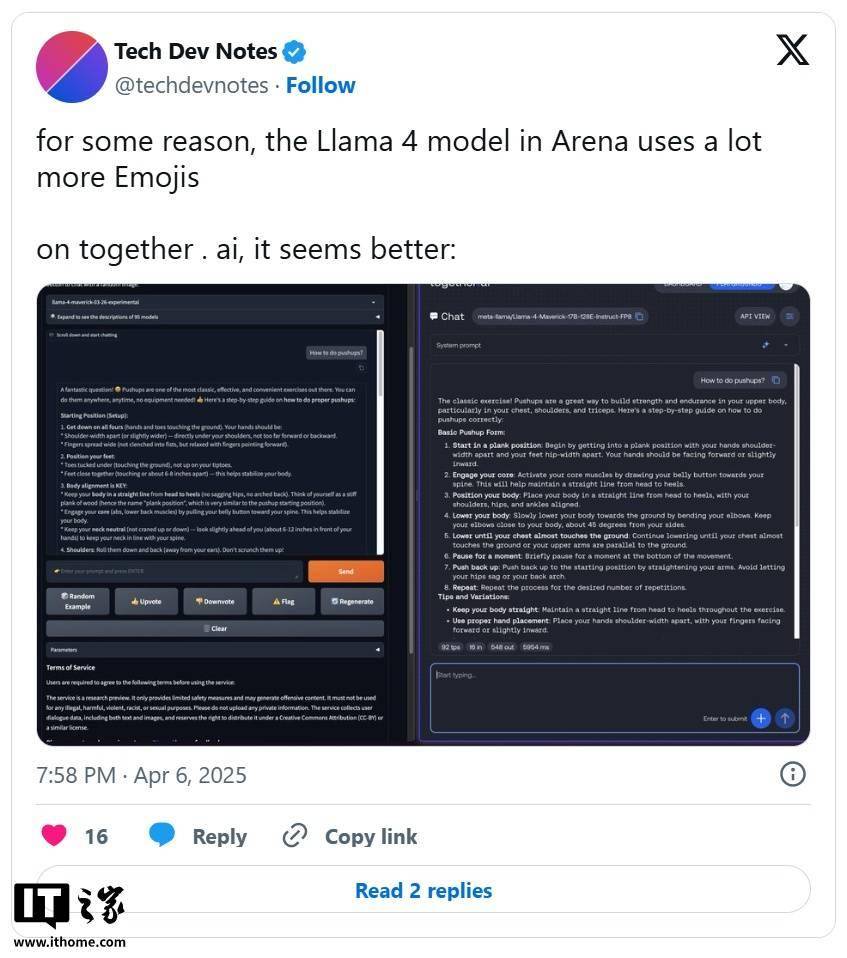
Meta 公司上周发布了一款名为 Maverick 的新旗舰 AI 模型,并在 LM Arena 测试中取得了第二名的成绩。然而,这一成绩的含金量却引发了诸多质疑。据多位 AI 研究人员在社交平台 X 上指出,Meta 在 LM Arena 上部署的 Maverick 版本与广泛提供给开发者的版本并不一致。 Meta 在其公告中明确提到,参与 LM Arena 测试的 Maverick 是一个“实验性聊天版本”。而根据官方 Llama 网站上公布的信息,Meta 在 LM Arena 的测试中所使用的实际上是“针对对话性优化的 Llama 4 Maverick”。这表明,该版本经过了专门的优化调整,以适应 LM Arena 的测试环境和评分标准。 然而,LM Arena 作为一项测试工具,其可靠性本身就存在一定的争议。尽管如此,以往 AI 公司通常不会对模型进行专门的定制或微调,以在 LM Arena 上获得更高的分数,至少没有公开承认过这种做法。而 Meta 此次的行为。 这种对模型进行针对性优化,然后只发布一个“普通版”的行为,给开发者带来了诸多困扰。因为这使得开发者难以准确预测该模型在特定场景下的实际表现。此外,这种行为也具有一定的误导性。理想情况下,尽管现有的基准测试存在诸多不足,但它们至少能够为人们提供一个关于单一模型在多种任务中优缺点的概览。 事实上,研究人员在 X 上已经观察到了公开可下载的 Maverick 版本与 LM Arena 上托管的模型之间存在显著的行为差异。例如,LM Arena 版本似乎更倾向于使用大量的表情符号,并且给出的答案往往冗长且拖沓。 截至IT之家发稿,Meta 公司以及负责维护 LM Arena 的 Chatbot Arena 组织暂未对此做出回应。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-4-7 20:33:35
发表于 2025-4-7 20:33:35

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





