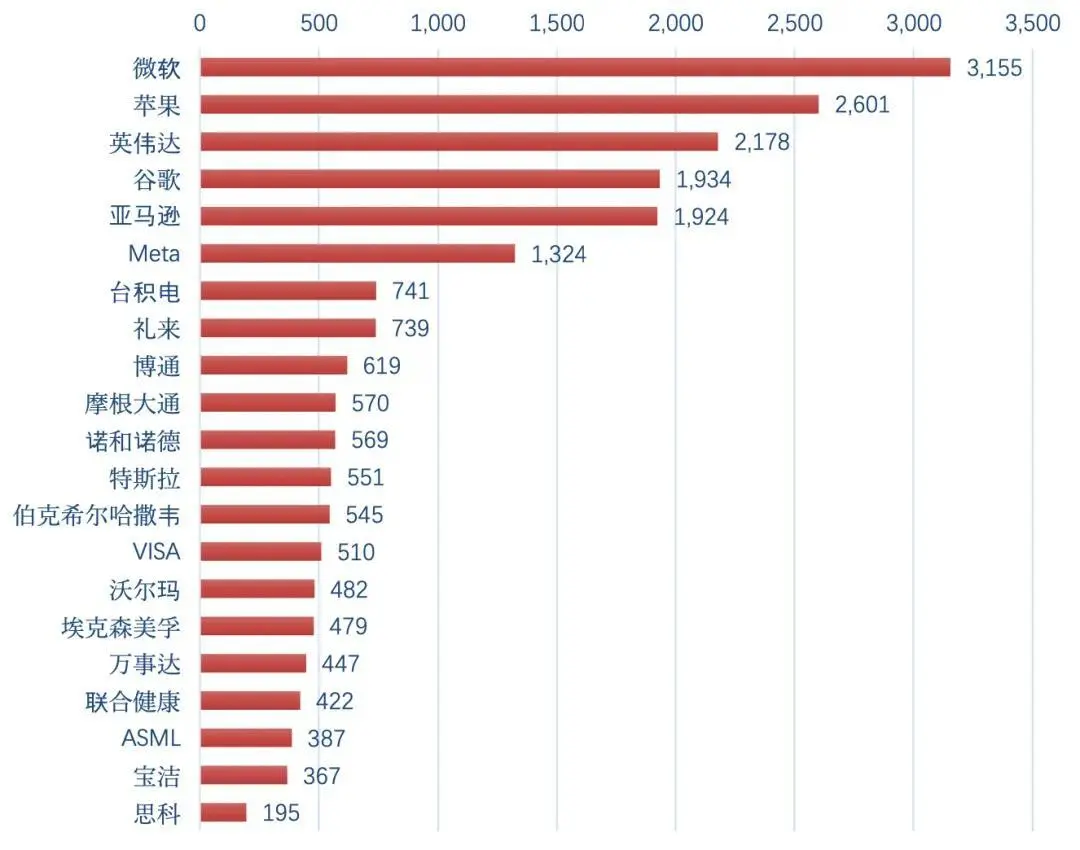
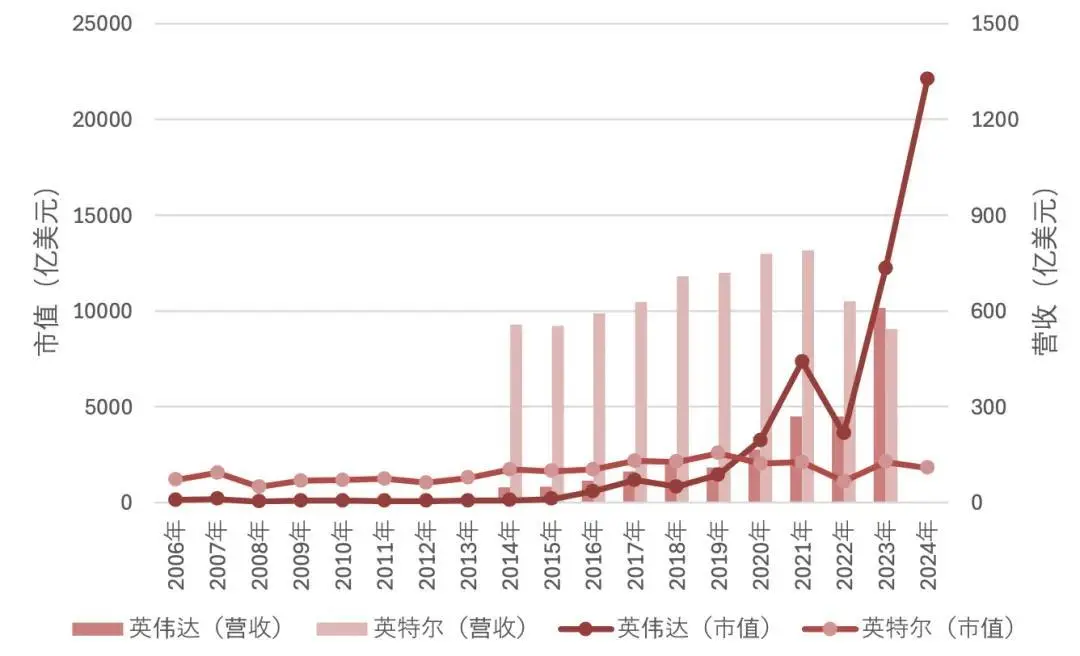
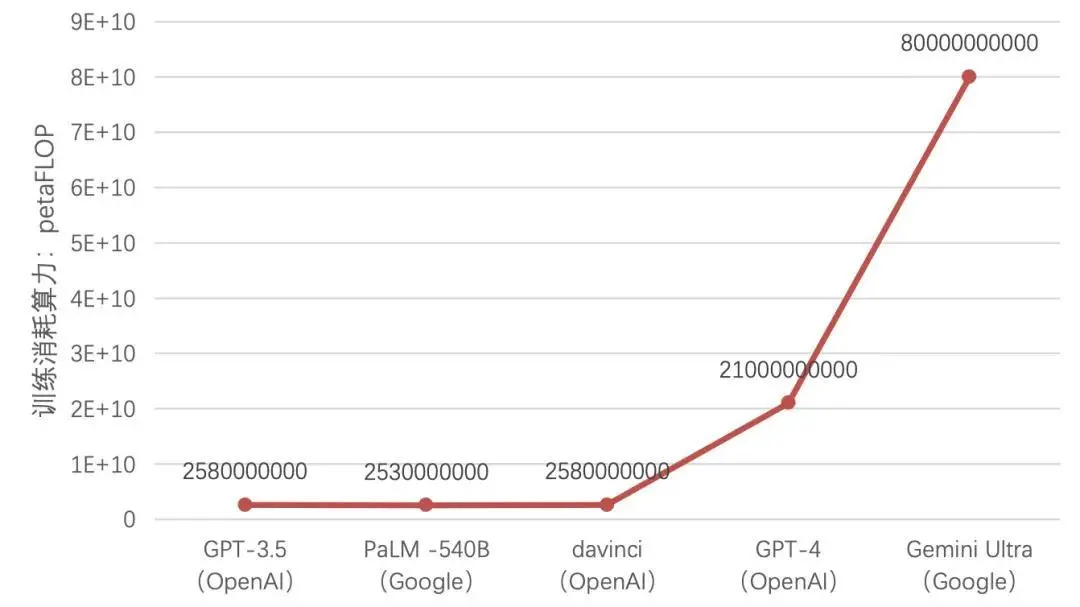
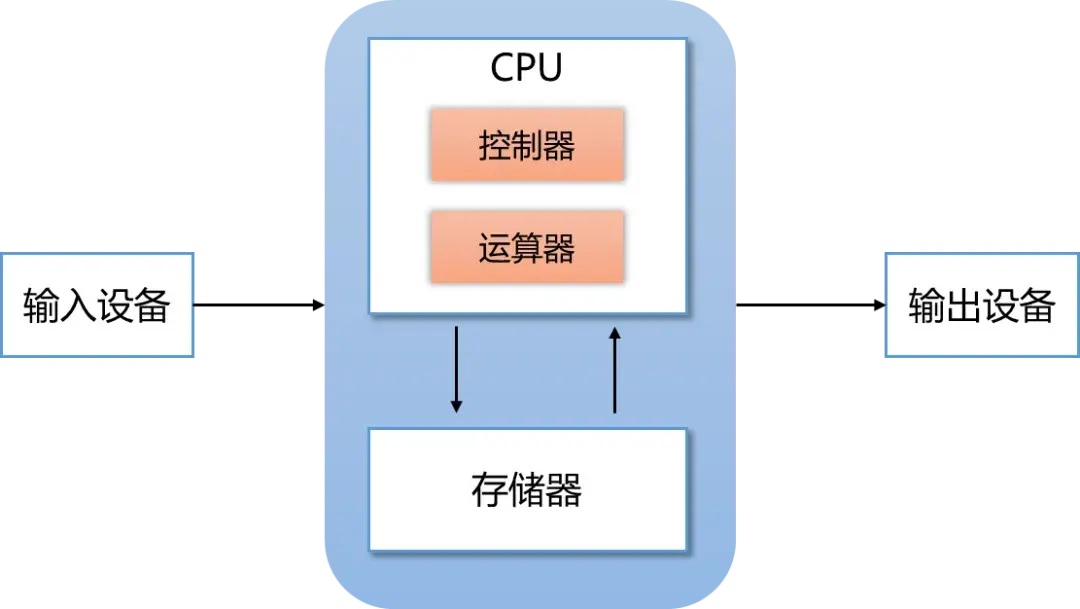
|
106| 3
|
[дёҡз•Ң] AIиҠҜзүҮжҲҳдәүпјҡиӢұдјҹиҫҫжҳҜ科жҠҖд№Ӣе·…пјҢиҝҳжҳҜдёӢдёҖдёӘжҖқ科пјҹ |
| ||
зӣёе…іеё–еӯҗ
|
||
| ||
| ||
APP|жүӢжңәзүҲ|е°Ҹй»‘еұӢ|е…ідәҺжҲ‘们|иҒ”зі»жҲ‘们|жі•еҫӢжқЎж¬ҫ|жҠҖжңҜзҹҘиҜҶеҲҶдә«е№іеҸ°
GMT+8, 2024-6-8 00:07 , Processed in 0.218400 second(s), 12 queries , Redis On.
Powered by Discuz!
© 2006-2023 smzj.net



 IPеҪ’еұһең°
IPеҪ’еұһең° йӣ·иҫҫеҚЎ
йӣ·иҫҫеҚЎ еҸ‘иЎЁдәҺ 2024-5-13 16:02:27
еҸ‘иЎЁдәҺ 2024-5-13 16:02:27








 жҸҗеё–еҚЎ
жҸҗеё–еҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ й”Ғеё–еҚЎ
й”Ғеё–еҚЎ и§Јй”ҒеҚЎ
и§Јй”ҒеҚЎ жҳҫзӣ®еҚЎ
жҳҫзӣ®еҚЎ еҚғж–ӨйЎ¶
еҚғж–ӨйЎ¶





