爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
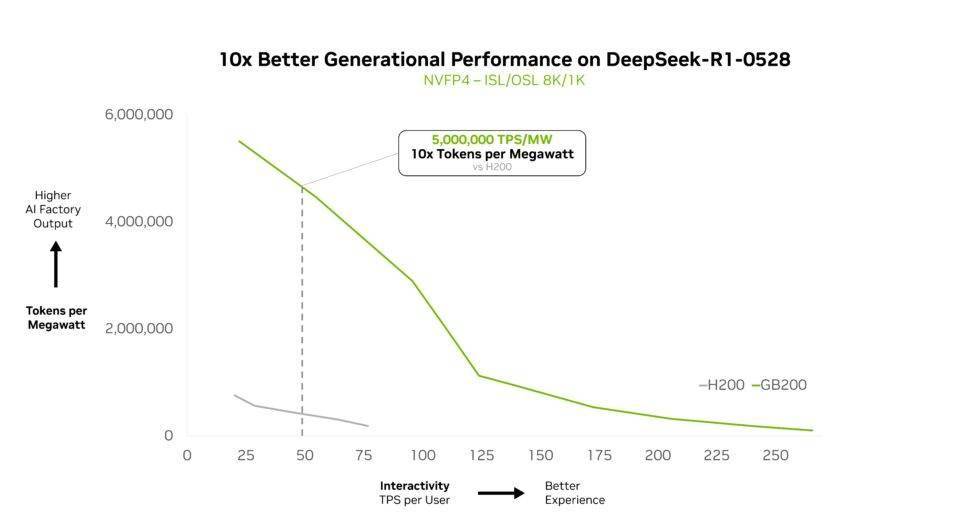
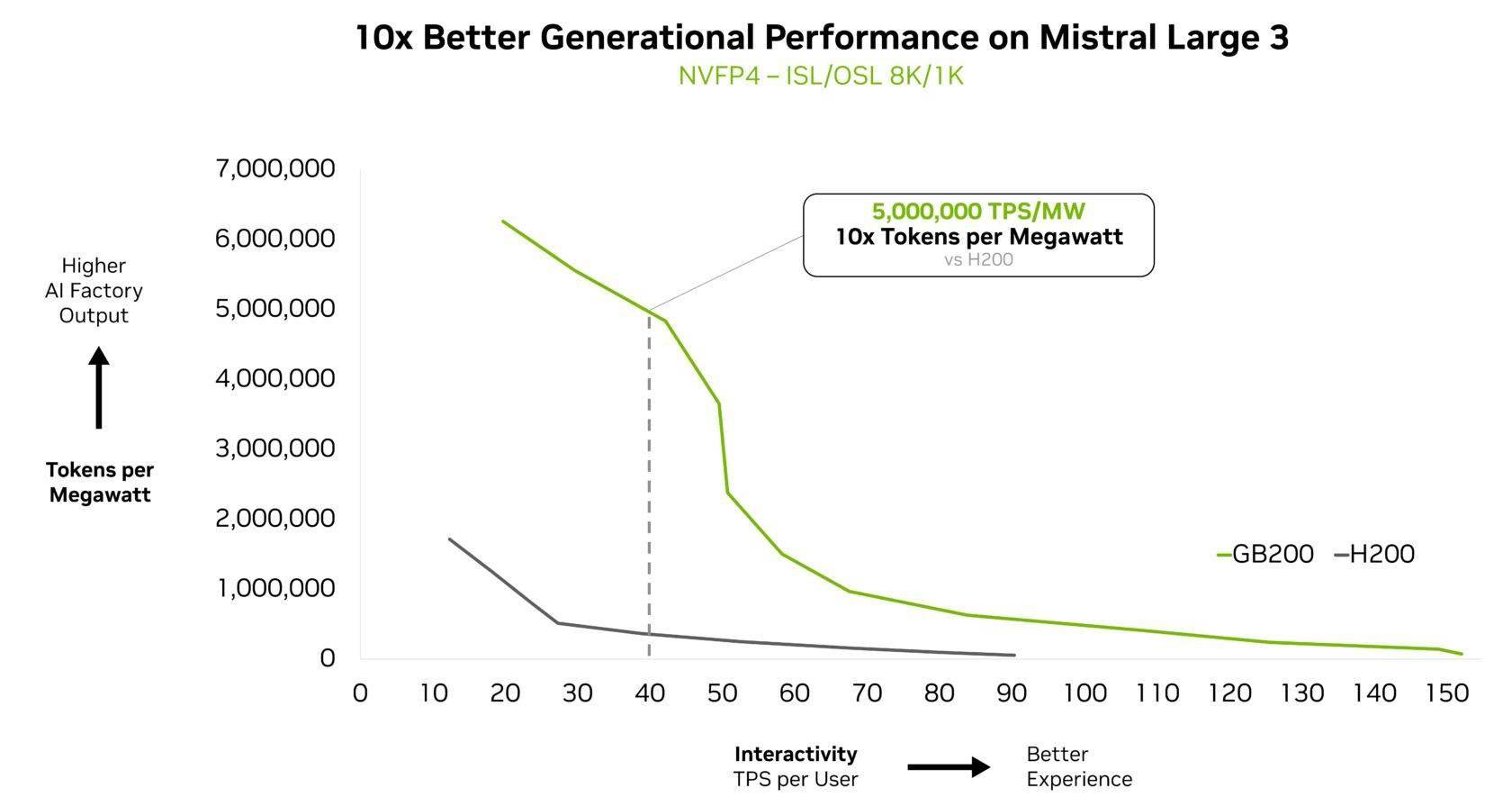
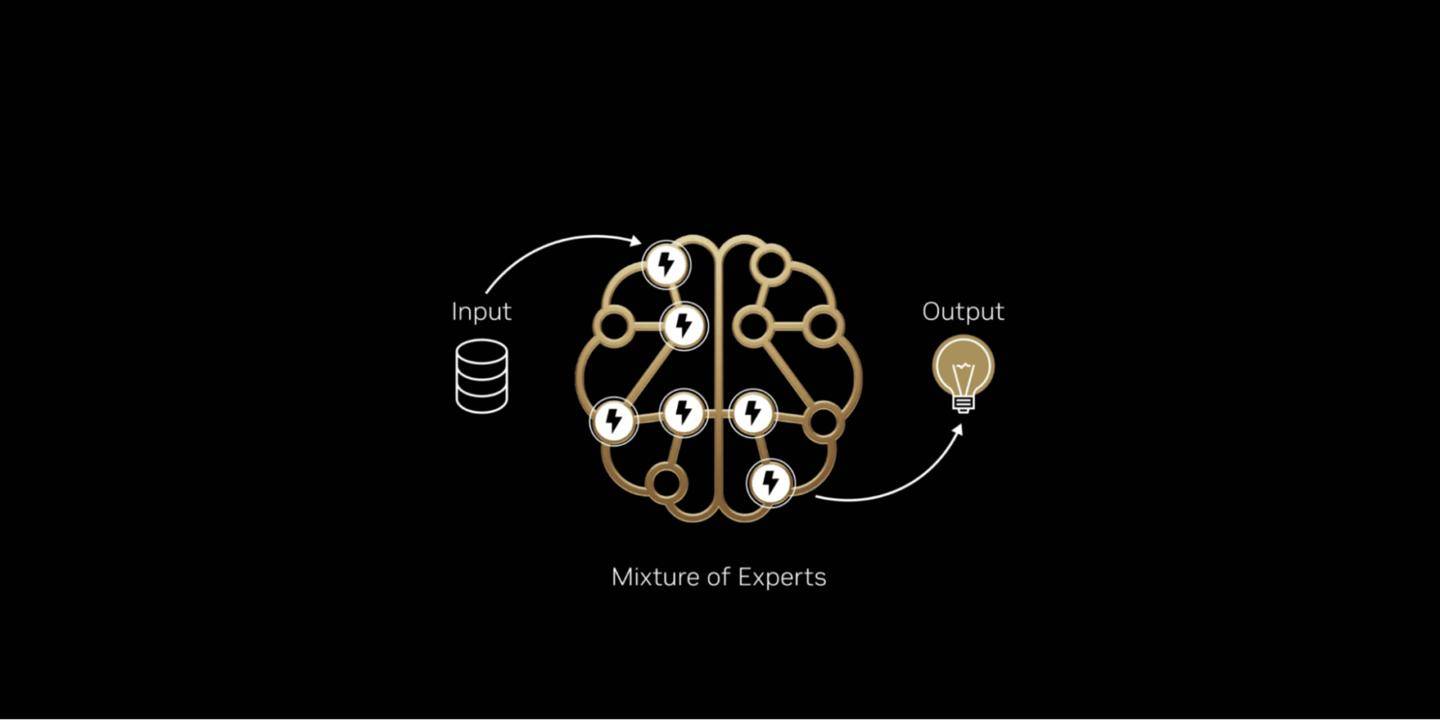
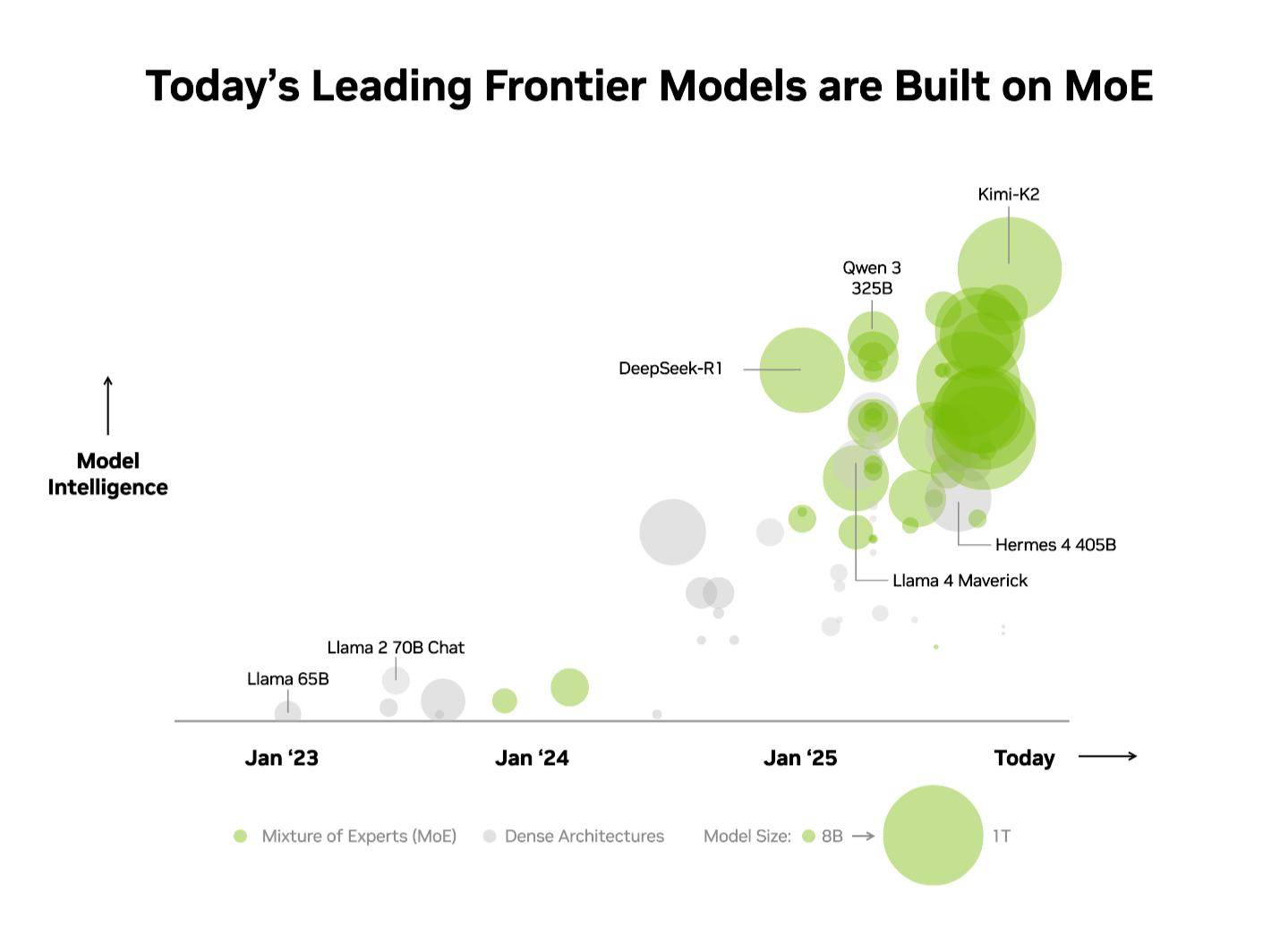
科技媒体 Wccftech 昨日(12 月 3 日)发布博文,报道称在“混合专家”模型上,英伟达的 GB200 NVL72 AI 服务器取得重大性能突破。 基于开源大语言模型 Kimi K2 Thinking、Deepseek-R1-0528、Mistral Large 3 测试,相比上一代 Hopper HGX 200 性能提升 10 倍。 IT之家注:混合专家模型(MoE)是一种高效的 AI 大模型架构。它不像传统模型那样在处理每个任务时都动用全部“脑力”(参数),而是像一个专家团队,根据任务类型只激活一小部分最相关的“专家”(参数子集)来解决问题。这样做能显著降低计算成本,提高处理速度。 就像人脑使用特定区域执行不同任务一样,混合专家模型使用路由器来选择最相关的专家来生成每个 token。 自 2025 年初以来,几乎所有领先的前沿模型都采用 MoE 设计 英伟达为了解决 MoE 模型扩展时遇到的性能瓶颈,采用了“协同设计”(co-design)的策略,该方法整合了 GB200 的 72 芯片配置、高达 30TB 的快速共享内存、第二代 Transformer 引擎以及第五代 NVLink 高速互联技术。 通过这些技术的协同工作,系统能够高效地将 Token 批次拆分并分配到各个 GPU,同时以非线性速率提升通信量,从而将专家并行计算(expert parallelism)提升至全新水平,最终实现了性能的巨大飞跃。 除了硬件层面的协同设计,英伟达还实施了多项全栈优化措施来提升 MoE 模型的推理性能。例如,NVIDIA Dynamo 框架通过将预填充(prefill)和解码(decode)任务分配给不同的 GPU,实现了任务的解耦服务,允许解码阶段以大规模专家并行方式运行。 同时,系统还采用了 NVFP4 格式,这种数据格式在保持计算精度的同时,进一步提高了性能和效率,确保了整个 AI 计算流程的高效稳定。 该媒体指出,此次 GB200 NVL72 取得的性能突破,对英伟达及其合作伙伴具有重要意义。这一进展成功克服了 MoE 模型在扩展时面临的计算瓶颈,从而能够满足日益增长的 AI 算力需求,并巩固了英伟达在 AI 服务器市场的领先地位。 GB200 NVL72,图源:英伟达
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于
发表于 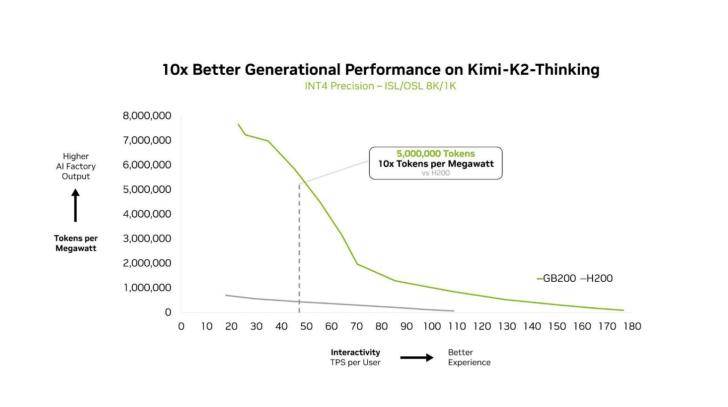



 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





