爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
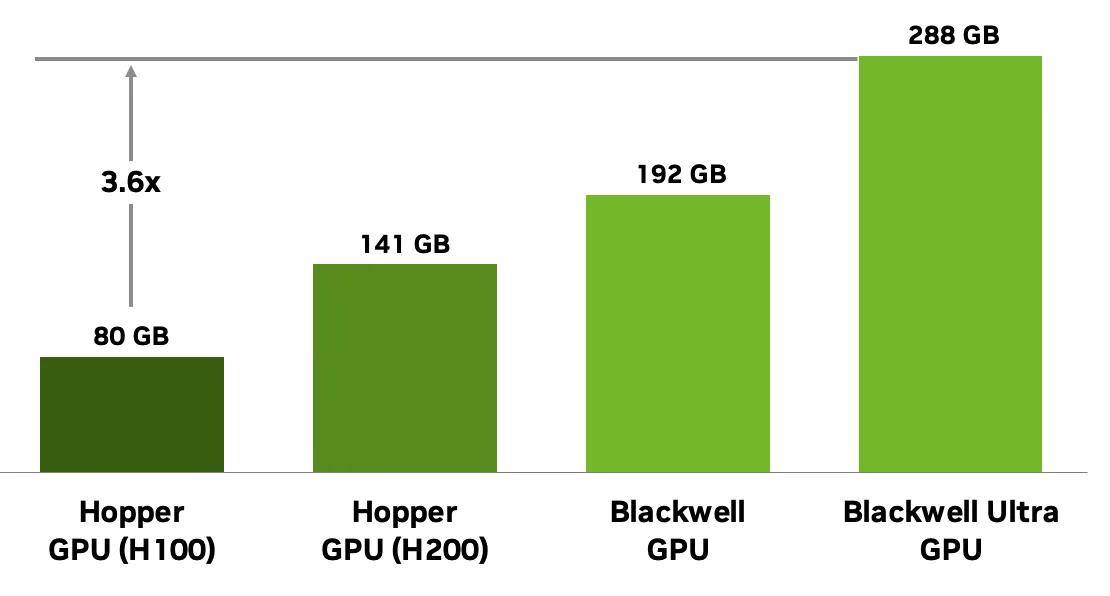
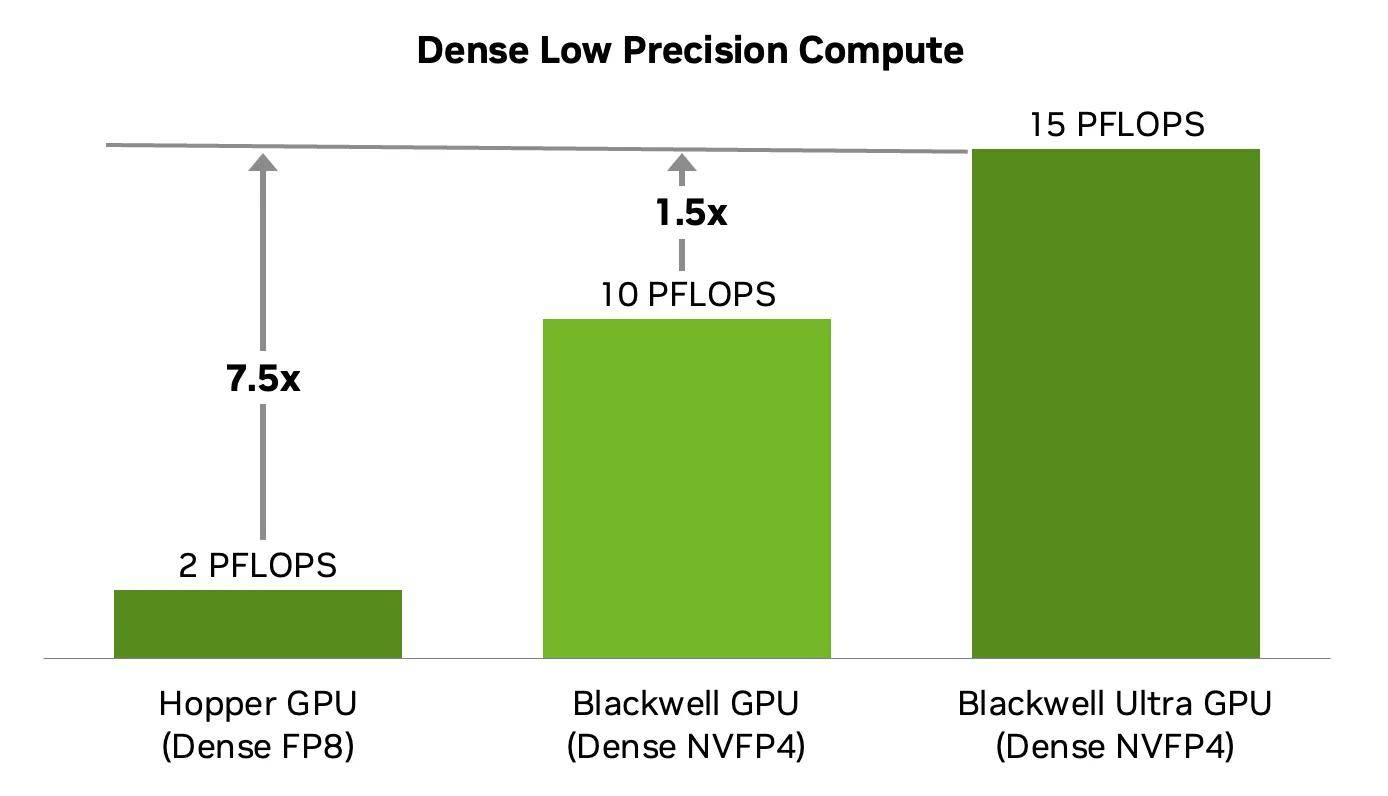
英伟达于 8 月 22 日发布博文,深入分析了其最快 AI 芯片 Blackwell Ultra GB300,比上一代 GB200 性能提升 50%。 该芯片采用双光罩(Reticle)设计、2080 亿晶体管、2 万个 CUDA 核心,并配备 288GB HBM3e 显存,带宽达 8TB/s。 GB300 采用双光罩(IT之家注:芯片光刻时单次曝光的最大尺寸单位,双光罩设计指通过互连技术将两颗大芯片作为一体运行)大芯片设计,通过 NV-HBI 高速互连将两颗芯片以 10TB/s 带宽连接为单颗 GPU。 该芯片基于台积电 4NP 工艺制造,集成 2080 亿晶体管,拥有 160 个 SM 单元,每个 SM 共有 128 个 CUDA 内核,总计 20480 个 CUDA 核心与 640 个第五代 Tensor 核心,并具备 40MB TMEM。 在存储方面,GB300 配备 288GB HBM3e 显存,带宽达 8TB/s,较 GB200 的 192GB 大幅提升,8 组堆叠显存通过 8192-bit 位宽连接,可容纳 3000 亿以上参数模型,支持更长的上下文长度及更高计算效率。 互连方面,Blackwell Ultra 支持第五代 NVLink,实现每 GPU 1.8TB/s 双向带宽,最多支持 576 GPU 互连;PCIe Gen6 接口提供 256GB/s 带宽,并支持与 Grace CPU 的 NVLink-C2C 协同。企业特性还包括多实例 GPU(MIG)分区、安全计算和 AI 预测运维功能。 在系统层面,Grace Blackwell Ultra 超级芯片将一颗 Grace CPU 直连两颗 GPU,构成 GB300 NVL72 机架系统,峰值算力可达 1.1 EFLOPS FP4。 安全与管理方面,GB300 搭载升级版 GigaThread 调度引擎,支持多实例 GPU(MIG)灵活分配显存资源,并引入机密计算与 TEE-I/O 特性保障 AI 模型与数据安全。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-8-25 22:46:58
发表于 2025-8-25 22:46:58



 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





