|
|
爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册
x
在接触数据采标行业过程中,黑智听到一个陆奇和河南标注工厂的故事。
据悉,大部分河南标注工厂用的是百度的标注工具,干的是百度的活。陆奇掌旗百度时,放出了大量采标需求。当时,活不难(准确率只有90%),标注的利润空间可以达到60%—70%。有些企业盲目扩张,一下子招了几百人;陆奇离开后,百度需求恰也减少。2018年下半年,准确率又普遍提高至95%-96%,活难干了。这些工厂只会百度的标注工具,很难接别家的业务,因此死了一批。没有死的工厂不得不裁员,目前处于艰难转型中。
当河南标注工厂艰难转型时,张三的标注公司却正式营业。公司初建,百事繁杂,前几天,黑智才在中午空闲时间,联系上他。他告诉黑智,两个年前的单子需要返工,一直在忙。对于初建公司,忙比闲好。如果有一天空闲下来,张三说他晚上都会睡不着觉,“一天没活干,几千块钱就打水漂了。一个月得支出15万(注:目前,公司有65名员工)。”
在他看来,标注行业是一个苦行业,“前半年,一定会赔钱的,你要做好一个人赔一万块钱的准备。”他笑着告诉黑智,“如果你和谁有仇,就劝他干标注吧。”这是标注圈有名的段子。
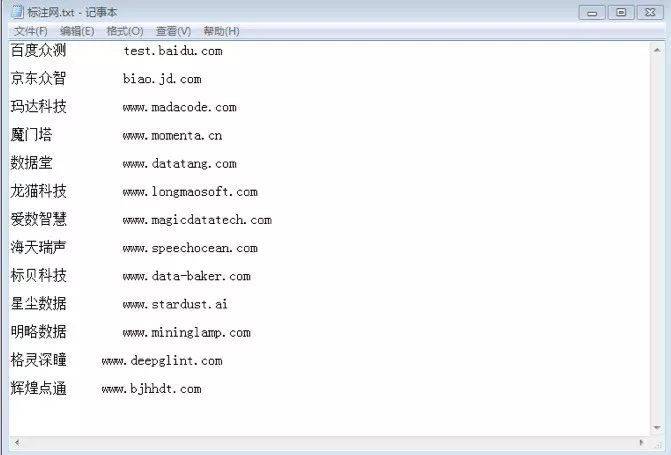
标注圈说大不大,说小也不小,分了四个梯队。张三说,他的公司属于第三梯队。第一梯队,比如百度众测、京东众智等。第二梯队,比如龙猫数据、Testin云测、倍赛 BasicFinder、数据堂等。他将第二梯队和第三梯队的关系,比做小房地产开放商和搬砖工人。第三梯队之下,是数量巨大的小作坊,团队规模在3-5人之间。
标注行业又是一个有前景的新生行业。
新生意味着不确定与无限可能,“干标注就像将水倒进一个水桶里,每拉一个框就是添一碗水。目前,谁也不知道还能添多久,只有水溢出来时,才知道。”这并不妨碍张三设计未来,“第一步,现阶段先服务好第二梯队,以后搞一个平台,把公司做成第二梯队。”
300亿市场与转折点
数据采集、标注市场有多大?300亿元。
1984年前后,这个市场就出现了。欣博友的公司是众多公司中的一家。当时,这些公司更像一个“录入公司”——将纸质内容电子化,而不是标注公司。“录入”是一个劳动密集型的工作,一家公司需要雇佣很多人来做这件事。智联招聘显示,欣博友在公司人数项上,勾选的是“1000—9999”。
和欣博友不同,海天瑞声成立于1998年,做的是语音标注,自建了很多语音库,业内人士告诉i黑马&黑智,重复销售以前做的语音库是海天瑞声比较大一块业务。数据堂成立于2011年,通常外界对其最深印象是“它是国内最大的数据交易平台”。这和其起家业务相关。
2015年前后,随着以榜单中的人工智能公司TOP50的强势崛起,数据标注和采集需求逐渐多了起来。这个市场才真正意义上形成,也即前面提到的四个梯队。他们作为乙方,进入到这个日益扩大的市场,为估值超10亿美金的AI独角兽服务,教能够改变世界的人工智能产品学习。
01 得数据者得AI的天下
数据是AI公司的必需品。就像人每天需要一日三餐,而AI模型也每天需要数据的喂养。数据和AI模型的关系,倍赛 BasicFinder创始人兼CEO杜霖理解深刻。高中期间,他开始研究计算机视觉,高三发表了论文。大学期间,他也一直在做相关的研究。他知道数据对于AI模型的重要性,并得出“AI建模没有门槛,数据才是门槛”的结论。
在他看来,现阶段的人工智能是简单的认知智能。“认知智能就是帮你去识别、分类这个世界。分类器的构造是个数学问题,就是由数据堆起来的。”“深度学习本质上是个数学问题,是由大量的样本空间数据反向构造分类器的系数空间的过程。你要有很多样本,什么叫样本?知道正确答案的才叫样本。这跟我们小时候求多样式、求系数式是一个道理。我们要有很多空间中的已知点,才能拟合成一个多样式。同理,深度学习也是这个模式,也需要大量样本,也即标定好的数据。”
于是,杜霖认准了“在现阶段工业界的AI应用研发,标数据是一定跳不过去的,可能10年之内都要依赖于标数据。”数据对于AI的重要性如斯,但数据的标注和采集公司并没有学界、业界、资本甚至是媒体的认可,光环一开始便属于那些做模型研发的AI公司,比如商汤科技、旷视科技等。
“一个公司做成了很好的人工智能产品,大家都会说人工智能算法牛或者科学家牛,但从没见人说数据收集得好的。”Testin云测VP贾宇航说。贾宇航告诉i黑马&黑智,不但镁光灯照不到,数据采标还是个“苦活”。苦到没有人想去做。它很像移动互联网,产品好,没人想到军功章有APP测试者一份。一旦出了问题,第一个被责备的一定是做测试的部门。
02 300亿元数据采标市场
数据对于AI公司的重要性不言而喻。据悉,AI公司投入10%—15%的经费用于数据采标。也有人提到,这一比例为20%—30%。
2018年,中国AI公司的总融资规模达到千亿元以上,数据采标的市场约为100亿元—300亿元。其中,有三分之一是AI公司内部的标注部门之间消化的,有一些会被商务流程外包公司瓜分,剩下的25%—33%流向专门做数据采标的第三方公司。目前,AI融资规模约以每年25%的速度在增长。
随着AI技术门槛的降低,越来越多的公司开源了自己的框架,把数据喂进去就能出来一个模型。越来越多的头部垂直公司开始建立AI部门,之前它们多会把业务交给做AI模型的公司来做,这两年,龙猫数据、Testin云测、倍赛 BasicFinder的很多客户不是来自AI行业的客户,而是传统公司的AI业务部门。龙猫数据创始人兼CEO昝智认为从这个角度来看,市场规模并不好算,BAT、小米、京东、TMD等互联网公司和传统行业里的传统企业,它们会拿出多少预算做AI,不得而知。唯一可以肯定的是,这两三年,数据采标的市场规模越来越大。
这两三年,AI模型对数据采标的复杂度和精细度要求也越来越高了。比如说,现在,做一个人脸拉框,人脸的拉框精度要求在五像素以内或者三像素以内;又或是,整批数据精确度需在97%或者99%以上。贾宇航认为,精度的提高是AI行业发展的必然结果。对于AI行业,有一句话叫 Garbage in, Garbage out,低精度的标注数据对于算法没有任何意义。只有能持续输出高精度采标数据,才是一个能持续保持竞争优势的服务商。
第二,更庞大、更多样的数据规模。庞大在于数据量会更大,以传感器为例,随着传感器成本下降,并被大量应用,将有更多大量的数据需要被标记;更多样指的是更丰富的数据维度,在今年的CES展上,松下推出的智能家居解决方案,不仅仅通过电视上的摄像头观测人脸的疲劳度,还通过椅子上的电容传感器,去检测人的心跳。而之前,疲劳检测只是通过摄像头捕捉人脸。将来,更多维度的数据将被收集,不单单是2D的图象、声音,3D的激光雷达以及心跳数据等也将被纳入到采标的范围内。
03 转折点
需求侧的变化,不可避免地在供给侧引起不小的地震。供给侧开始从密集劳动型行业向新产业、新模式——工具+众包转型。洗牌开始了,数据采标迎来了下半场。
受负面影响最大的第四梯队。无论是采标的复杂还是要求愈高的精度,对于它们来说都不是好消息。去年中旬以来,每天十几、二十几家小作坊要求挂靠在倍赛 BasicFinder旗下,这说明小作坊已经失去业务的来源。“他们靠低质量数据和低价抢市场的模式,已经不能持续了。因为AI工程师不能接受低质量的数据,也不能接受不靠谱的交期。”杜霖说。
张三认为,第四梯队坏了规矩。他们先靠低价四处抢单子,而后内测什么样的项目能够在单位时间内产出最多,再去做这个项目。其它项目,则被分包给更小的团队去做。质量难以保证。“他们不算房租、管理等,只核算人工费用。他们的逻辑是一个人一天50块钱,高于这个价就是赚的。于是他们就报100元的单价。而第三梯队需要承担房租,税收、管理费用以及每天的喝水吃饭等乱七八糟的消耗,至少报200元的单价,才可以做。”
早期,第四梯队靠着这种方式,赚了一些钱,回收了硬件成本,并有结余。但2018年初,第二梯队开始做店测,“看看你有多少人,看看你的场地。你不专业,行业正在慢慢把你淘汰掉。”淘汰,意味着没有业务来源,那么多人需要吃饭、拿工资,不专业的第四梯队危机便出现了。即便能够找到项目,采标项目的要求提高,比如准确度要达到95%甚至是99%以上,小作坊必须从团队中抽出一部分人脱产质检和最后的抽检,成本也会上升。
|
|



 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2019-3-16 15:07:05
发表于 2019-3-16 15:07:05

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





