|
|
зИ±зІСжКАгАБзИ±еИЫжДПгАБзИ±жКШиЕЊгАБзИ±жЮБиЗіпЉМжИСдїђйГљжШѓжКАжЬѓжОІ
жВ®йЬАи¶Б зЩїељХ жЙНеПѓдї•дЄЛиљљжИЦжЯ•зЬЛпЉМж≤°жЬЙиі¶еПЈпЉЯзЂЛеН≥ж≥®еЖМ

x
жЬђеЄЦжЬАеРОзФ± дЄНйХњеПґе≠РзЪДж†С дЇО 2023-12-5 21:05 зЉЦиЊС
жИСдїђйГљзЯ•йБУзљСзїЬдЄКзЪДзИђиЩЂйЭЮеЄЄе§ЪпЉМжЬЙеѓєзљСзЂЩжФґељХжЬЙзЫКзЪДпЉМжѓФе¶ВзЩЊеЇ¶иЬШиЫЫпЉИBaiduspiderпЉЙпЉМдєЯжЬЙдЄНдљЖдЄНйБµеЃИ robots иІДеИЩеѓєжЬНеК°еЩ®йА†жИРеОЛеКЫпЉМињШдЄНиГљдЄЇзљСзЂЩеЄ¶жЭ•жµБйЗПзЪДжЧ†зФ®зИђиЩЂпЉМжѓФе¶ВеЃЬжРЬиЬШиЫЫпЉИYisouSpiderпЉЙпЉИжЬАжЦ∞и°•еЕЕпЉЪеЃЬжРЬиЬШиЫЫеЈ≤襀 UC з•Юй©ђжРЬ糥жФґиі≠пЉБжЙАдї•жЬђжЦЗеЈ≤еОїжОЙеЃЬжРЬиЬШиЫЫзЪДз¶Бе∞БпЉБ==>зЫЄеЕ≥жЦЗзЂ†)гАВжЬАињСеЉ†жИИеПСзО∞ nginx жЧ•ењЧдЄ≠еЗЇзО∞дЇЖе•ље§ЪеЃЬжРЬз≠ЙеЮГеЬЊзЪДжКУеПЦиЃ∞ељХпЉМдЇОжШѓжХізРЖжФґйЫЖдЇЖзљСзїЬдЄКеРДзІНз¶Бж≠ҐеЮГеЬЊиЬШиЫЫзИђзЂЩзЪДжЦєж≥ХпЉМеЬ®зїЩиЗ™еЈ±зљСеБЪиЃЊзљЃзЪДеРМжЧґпЉМдєЯзїЩеРДдљНзЂЩйХњжПРдЊЫеПВиАГгАВ
дЄАгАБApacheвС†гАБйАЪињЗдњЃжФє .htaccess жЦЗдїґдњЃжФєзљСзЂЩзЫЃељХдЄЛзЪД.htaccessпЉМжЈїеК†е¶ВдЄЛдї£з†БеН≥еПѓпЉИ2 зІНдї£з†БдїїйАЙпЉЙпЉЪ
еПѓзФ®дї£з†Б (1)пЉЪRewriteEngine On
| [tr][/tr]
RewriteCond %{HTTP_USER_AGENT} (^$|FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) [NC]
| [tr][/tr]
еПѓзФ®дї£з†Б (2)пЉЪSetEnvIfNoCase ^User-Agent$ .*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms) BADBOT
| [tr][/tr]
Order Allow,Deny
| [tr][/tr]
вС°гАБйАЪињЗдњЃжФє httpd.conf йЕНзљЃжЦЗдїґжЙЊеИ∞е¶ВдЄЛз±їдЉЉдљНзљЃпЉМж†єжНЃдї•дЄЛдї£з†Б жЦ∞еҐЮ / дњЃжФєпЉМзДґеРОйЗНеРѓ Apache еН≥еПѓпЉЪ
DocumentRoot /home/wwwroot/xxx
| [tr][/tr]
<Directory "/home/wwwroot/xxx">
| [tr][/tr]
SetEnvIfNoCase User-Agent ".*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" BADBOT
| [tr][/tr]
Order allow,deny
| [tr][/tr]
deny from env=BADBOT
| [tr][/tr]
дЇМгАБNginx дї£з†БињЫеЕ•еИ∞ nginx еЃЙи£ЕзЫЃељХдЄЛзЪД conf зЫЃељХпЉМе∞Же¶ВдЄЛдї£з†БдњЭе≠ШдЄЇ agent_deny.conf
cd /usr/local/nginx/conf
vim agent_deny.conf
#з¶Бж≠Ґ Scrapy з≠ЙеЈ•еЕЈзЪДжКУеПЦ
| [tr][/tr]
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
| [tr][/tr]
#з¶Бж≠ҐжМЗеЃЪ UA еПК UA дЄЇз©ЇзЪДиЃњйЧЃ
| [tr][/tr]
if ($http_user_agent ~* "FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" ) {
| [tr][/tr]
#з¶Бж≠ҐйЭЮ GET|HEAD|POST жЦєеЉПзЪДжКУеПЦ
| [tr][/tr]
if ($request_method !~ ^(GET|HEAD|POST)$) {
| [tr][/tr]
зДґеРОпЉМеЬ®зљСзЂЩзЫЄеЕ≥йЕНзљЃдЄ≠зЪД location / { дєЛеРОжПТеЕ•е¶ВдЄЛдї£з†БпЉЪ
е¶ВеЉ†жИИеНЪеЃҐзЪДйЕНзљЃпЉЪ
[marsge@Mars_Server ~]$ cat /usr/local/nginx/conf/zhangge.conf
| [tr][/tr]
try_files $uri $uri/ /index.php?$args;
| [tr][/tr]
#ињЩдЄ™дљНзљЃжЦ∞еҐЮ 1 и°МпЉЪ
| [tr][/tr]
include agent_deny.conf;
| [tr][/tr]
rewrite ^/sitemap_360_sp.txt$ /sitemap_360_sp.php last;
| [tr][/tr]
rewrite ^/sitemap_baidu_sp.xml$ /sitemap_baidu_sp.php last;
| [tr][/tr]
rewrite ^/sitemap_m.xml$ /sitemap_m.php last;
|
дњЭе≠ШеРОпЉМжЙІи°Ме¶ВдЄЛеСљдї§пЉМеє≥жїСйЗНеРѓ nginx еН≥еПѓпЉЪ
/usr/local/nginx/sbin/nginx -s reload
|
дЄЙгАБPHP дї£з†Бе∞Же¶ВдЄЛжЦєж≥ХжФЊеИ∞иііеИ∞зљСзЂЩеЕ•еП£жЦЗдїґ index.php дЄ≠зЪДзђђдЄАдЄ™ <?php дєЛеРОеН≥еПѓпЉЪ
//иОЈеПЦ UA дњ°жБѓ
| [tr][/tr]
$ua = $_SERVER['HTTP_USER_AGENT'];
| [tr][/tr]
//е∞ЖжБґжДП USER_AGENT е≠ШеЕ•жХ∞зїД
| [tr][/tr]
$now_ua = array('FeedDemon ','BOT/0.1 (BOT for JCE)','CrawlDaddy ','Java','Feedly','UniversalFeedParser','ApacheBench','Swiftbot','ZmEu','Indy Library','oBot','jaunty','YandexBot','AhrefsBot','MJ12bot','WinHttp','EasouSpider','HttpClient','Microsoft URL Control','YYSpider','jaunty','Python-urllib','lightDeckReports Bot');
| [tr][/tr]
//з¶Бж≠Ґз©Ї USER_AGENTпЉМdedecms з≠ЙдЄїжµБйЗЗйЫЖз®ЛеЇПйГљжШѓз©Ї USER_AGENTпЉМйГ®еИЖ sql ж≥®еЕ•еЈ•еЕЈдєЯжШѓз©Ї USER_AGENT
| [tr][/tr]
header("Content-type: text/html; charset=utf-8");
| [tr][/tr]
die('иѓЈеЛњйЗЗйЫЖжЬђзЂЩпЉМеЫ†дЄЇйЗЗйЫЖзЪДзЂЩйХњжЬ®жЬЙе∞П JJпЉБ');
| [tr][/tr]
foreach($now_ua as $value )
| [tr][/tr]
//еИ§жЦ≠жШѓеР¶жШѓжХ∞зїДдЄ≠е≠ШеЬ®зЪД UA
| [tr][/tr]
if(eregi($value,$ua)) {
| [tr][/tr]
header("Content-type: text/html; charset=utf-8");
| [tr][/tr]
die('иѓЈеЛњйЗЗйЫЖжЬђзЂЩпЉМеЫ†дЄЇйЗЗйЫЖзЪДзЂЩйХњжЬ®жЬЙе∞П JJпЉБ');
| [tr][/tr]
еЫЫгАБжµЛиѓХжХИжЮЬе¶ВжЮЬжШѓ vpsпЉМйВ£йЭЮеЄЄзЃАеНХпЉМдљњзФ® curl -A ж®°жЛЯжКУеПЦеН≥еПѓпЉМжѓФе¶ВпЉЪ
ж®°жЛЯеЃЬжРЬиЬШиЫЫжКУеПЦпЉЪ
curl -I -A 'YisouSpider' zhang.ge
|
ж®°жЛЯ UA дЄЇз©ЇзЪДжКУеПЦпЉЪ
ж®°жЛЯзЩЊеЇ¶иЬШиЫЫзЪДжКУеПЦпЉЪ
curl -I -A 'Baiduspider' zhang.ge
|
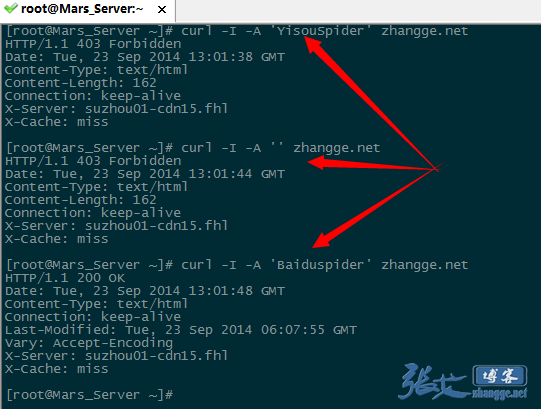
дЄЙжђ°жКУеПЦзїУжЮЬжИ™еЫЊе¶ВдЄЛпЉЪ
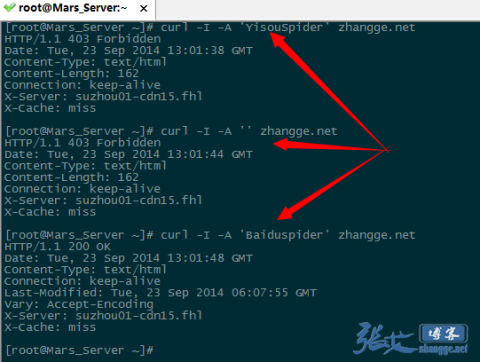
еПѓдї•зЬЛеЗЇпЉМеЃЬжРЬиЬШиЫЫеТМ UA дЄЇз©ЇзЪДињФеЫЮжШѓ 403 з¶Бж≠ҐиЃњйЧЃж†ЗиѓЖпЉМиАМзЩЊеЇ¶иЬШиЫЫеИЩжИРеКЯињФеЫЮ 200пЉМиѓіжШОзФЯжХИпЉБ
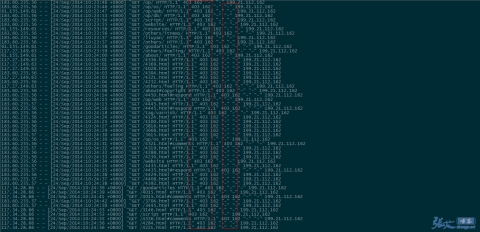
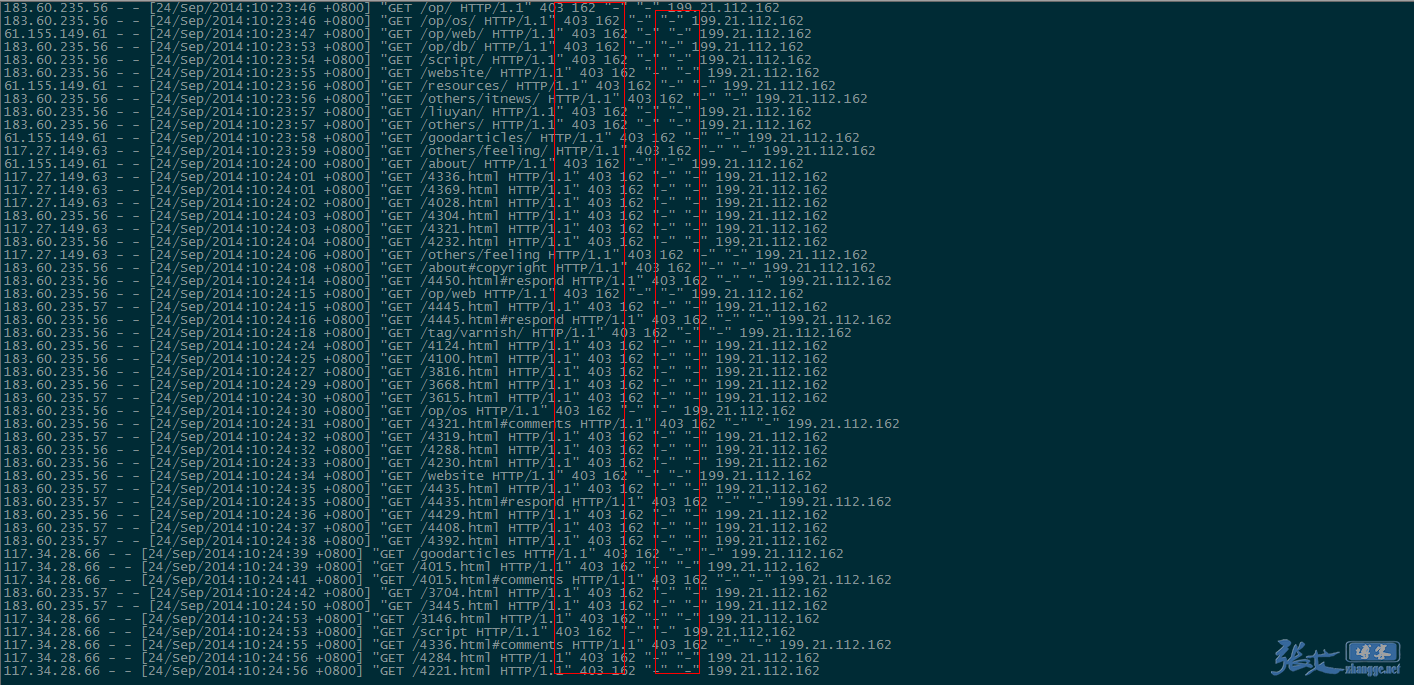
и°•еЕЕпЉЪзђђдЇМ姩пЉМжЯ•зЬЛ nginx жЧ•ењЧзЪДжХИжЮЬжИ™еЫЊпЉЪвС†гАБUA дњ°жБѓдЄЇз©ЇзЪДеЮГеЬЊйЗЗйЫЖ襀жЛ¶жИ™пЉЪ
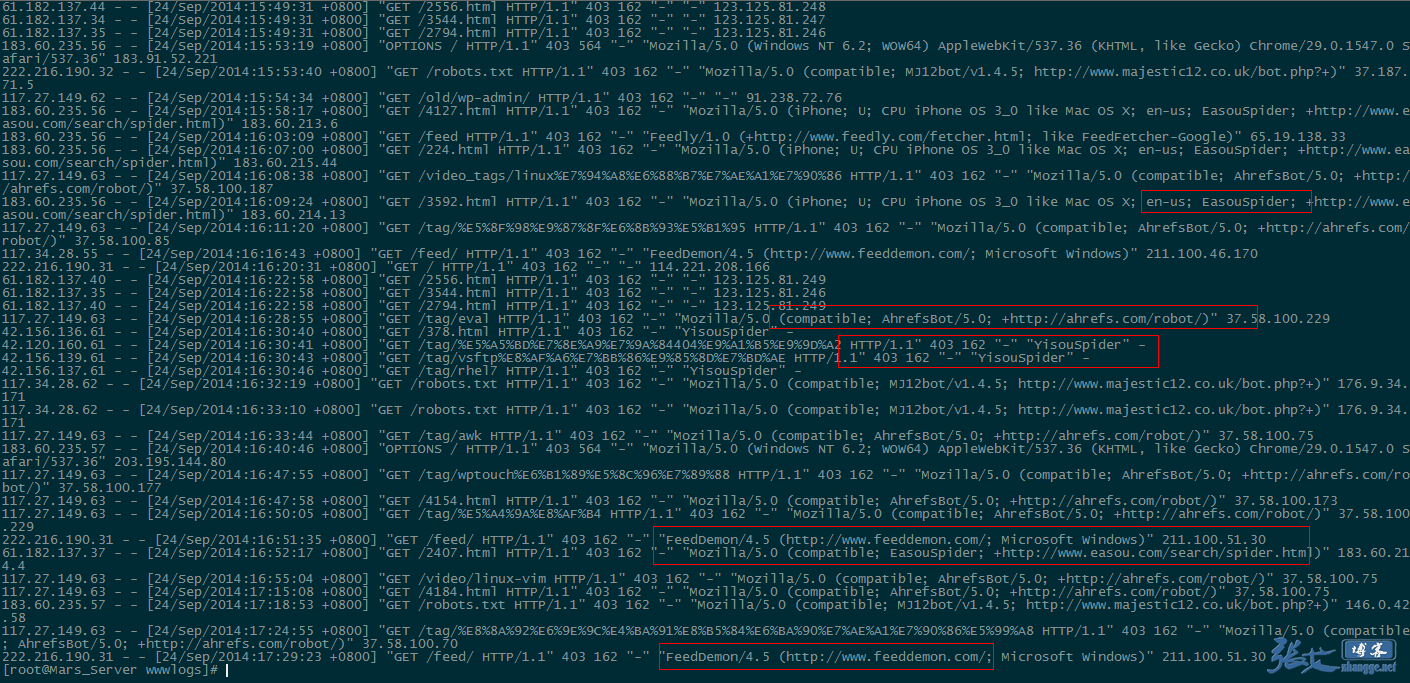
вС°гАБ襀з¶Бж≠ҐзЪД UA 襀жЛ¶жИ™пЉЪ
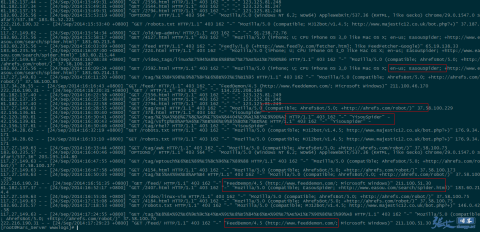
еЫ†ж≠§пЉМеѓєдЇОеЮГеЬЊиЬШиЫЫзЪДжФґйЫЖпЉМжИСдїђеПѓдї•йАЪињЗеИЖжЮРзљСзЂЩзЪДиЃњйЧЃжЧ•ењЧпЉМжЙЊеЗЇдЄАдЇЫж≤°иІБињЗзЪДзЪДиЬШиЫЫпЉИspiderпЉЙеРНзІ∞пЉМзїПињЗжߕ胥жЧ†иѓѓдєЛеРОпЉМеПѓдї•е∞ЖеЕґеК†еЕ•еИ∞еЙНжЦЗдї£з†БзЪДз¶Бж≠ҐеИЧи°®ељУдЄ≠пЉМиµЈеИ∞з¶Бж≠ҐжКУеПЦзЪДдљЬзФ®гАВ
дЇФгАБйЩДељХпЉЪUA жФґйЫЖдЄЛйЭҐжШѓзљСзїЬдЄКеЄЄиІБзЪДеЮГеЬЊ UA еИЧи°®пЉМдїЕдЊЫеПВиАГпЉМеРМжЧґдєЯ搥ињОдљ†жЭ•и°•еЕЕгАВ
FeedDemon еЖЕеЃєйЗЗйЫЖ
| [tr][/tr]
BOT/0.1 (BOT for JCE) sql ж≥®еЕ•
| [tr][/tr]
CrawlDaddy sql ж≥®еЕ•
| [tr][/tr]
Java еЖЕеЃєйЗЗйЫЖ
| [tr][/tr]
Jullo еЖЕеЃєйЗЗйЫЖ
| [tr][/tr]
Feedly еЖЕеЃєйЗЗйЫЖ
| [tr][/tr]
UniversalFeedParser еЖЕеЃєйЗЗйЫЖ
| [tr][/tr]
ApacheBench cc жФїеЗїеЩ®
| [tr][/tr]
Swiftbot жЧ†зФ®зИђиЩЂ
| [tr][/tr]
YandexBot жЧ†зФ®зИђиЩЂ
| [tr][/tr]
AhrefsBot жЧ†зФ®зИђиЩЂ
| [tr][/tr]
YisouSpider жЧ†зФ®зИђиЩЂпЉИеЈ≤襀 UC з•Юй©ђжРЬ糥жФґиі≠пЉМж≠§иЬШиЫЫеПѓдї•жФЊеЉАпЉБпЉЙ
| [tr][/tr]
MJ12bot жЧ†зФ®зИђиЩЂ
| [tr][/tr]
ZmEu phpmyadmin жЉПжіЮжЙЂжПП
| [tr][/tr]
WinHttp йЗЗйЫЖ cc жФїеЗї
| [tr][/tr]
EasouSpider жЧ†зФ®зИђиЩЂ
| [tr][/tr]
HttpClient tcp жФїеЗї
| [tr][/tr]
Microsoft URL Control жЙЂжПП
| [tr][/tr]
YYSpider жЧ†зФ®зИђиЩЂ
| [tr][/tr]
jaunty wordpress зИЖз†іжЙЂжППеЩ®
| [tr][/tr]
oBot жЧ†зФ®зИђиЩЂ
| [tr][/tr]
Python-urllib еЖЕеЃєйЗЗйЫЖ
| [tr][/tr]
Indy Library жЙЂжПП
| [tr][/tr]
FlightDeckReports Bot жЧ†зФ®зИђиЩЂ
| [tr][/tr]
zhang.ge/4458.html
|
|



 IPељТе±ЮеЬ∞
IPељТе±ЮеЬ∞ йЫЈиЊЊеН°
йЫЈиЊЊеН° еПСи°®дЇО 2023-12-5 20:59:47
еПСи°®дЇО 2023-12-5 20:59:47
 жПРеЄЦеН°
жПРеЄЦеН° зљЃй°ґеН°
зљЃй°ґеН° йФБеЄЦеН°
йФБеЄЦеН° иІ£йФБеН°
иІ£йФБеН° жШЊзЫЃеН°
жШЊзЫЃеН° еНГжЦ§й°ґ
еНГжЦ§й°ґ