爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
阿里通义千问今天(11 月 28 日)发布《QwQ: 思忖未知之界》博文,推出了 QwQ-32B-Preview 实验性研究模型,在数学和编程领域,尤其在需要深度推理的复杂问题上,具备卓越的 AI 推理能力。 它是少数能与 OpenAI 的 o1 匹敌的模型之一,并且是第一个能以宽松许可证下载的模型。QwQ-32B-Preview 在 Apache 2.0 许可证下“公开”可用,这意味着它可以用于商业应用。 QwQ 愿景 阿里通义千问团队表示“思考、质疑、理解,是人类探索未知的永恒追求”,而 QwQ 犹如一位怀抱无尽好奇的学徒,以思考和疑问照亮前路。 模型局限性 阿里通义千问团队首先表明 QwQ 模型具备局限性,仍在学习如何行走于理性之路,它的思绪偶尔飘散,答案或许未尽完善,智慧仍在积淀。 IT之家附上原文中对该模型的局限性介绍如下: 语言切换问题:模型可能在回答中混合使用不同语言,影响表达的连贯性。 推理循环:在处理复杂逻辑问题时,模型偶尔会陷入递归推理模式,在相似思路中循环。这种行为虽然反映了模型试图全面分析的努力,但可能导致冗长而不够聚焦的回答。 安全性考虑:尽管模型已具备基础安全管控,但仍需要进一步增强。它可能产生不恰当或存在偏见的回答,且与其他大型语言模型一样,可能受到对抗攻击的影响。我们强烈建议用户在生产环境中谨慎使用,并采取适当的安全防护措施。 能力差异:QwQ-32B-Preview 在数学和编程领域表现出色,但在其他领域仍有提升空间。模型性能会随任务的复杂度和专业程度而波动。我们正通过持续优化,努力提升模型的综合能力。
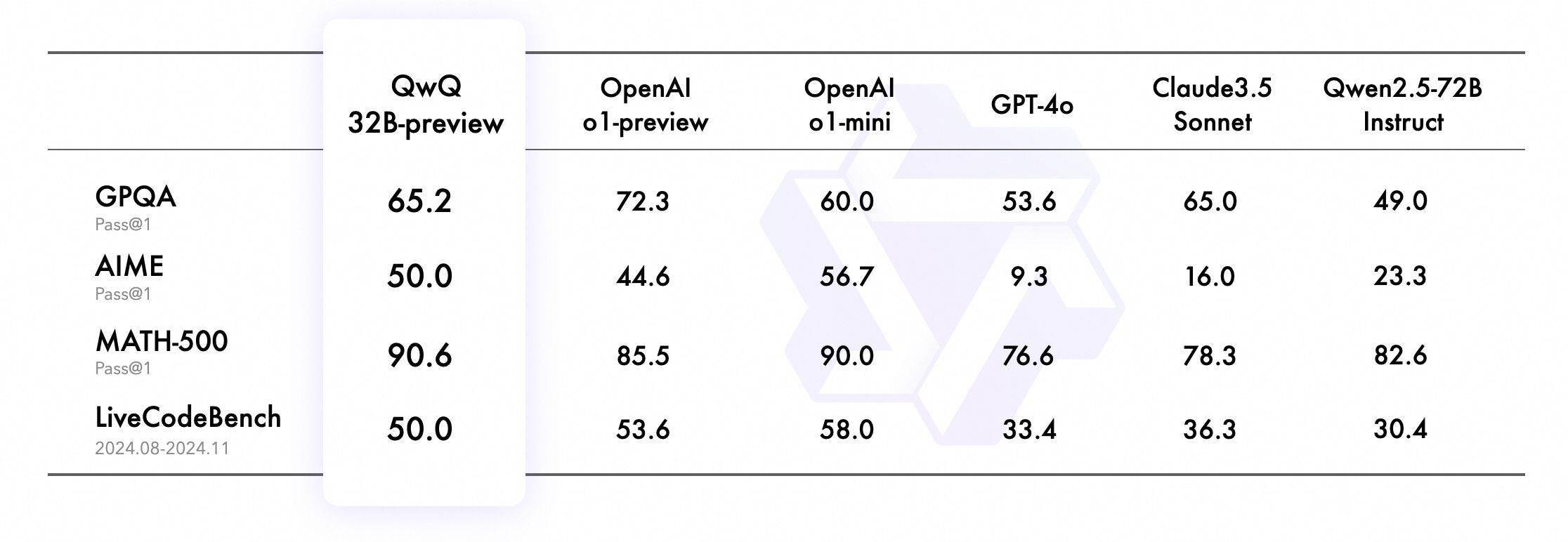
模型表现QwQ-32B-Preview 包含 325 亿个参数,能够处理最长 32000 个 tokens 的提示词;在 AIME 和 MATH 基准测试中,它的表现优于 OpenAI 的两个推理模型 o1-preview 和 o1-mini。 GPQA 该基准是一个通过小学级别问题评估高阶科学解题能力的评测集,旨在考察科学问题解决能力。QwQ-32B-Preview 评分为 65.2%,展示了研究生水平的科学推理能力。 AIME 该基准涵盖算术、代数、计数、几何、数论、概率等中学数学主题的综合评测,测试数学问题解决能力。QwQ-32B-Preview 评分为 50.0%,证明了强大的数学问题解决技能。 MATH-500 该基准包含 500 个测试样本的 MATH 评测集,全面考察数学解题能力。QwQ-32B-Preview 成绩为 90.6%,体现了在各类数学主题上的全面理解。 LiveCodeBench 该基准评估真实编程场景中代码生成和问题解决能力的高难度评测集。QwQ-32B-Preview 成绩为 50.0%,验证了在实际编程场景中的出色表现。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2024-11-28 20:45:36
发表于 2024-11-28 20:45:36
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





