爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
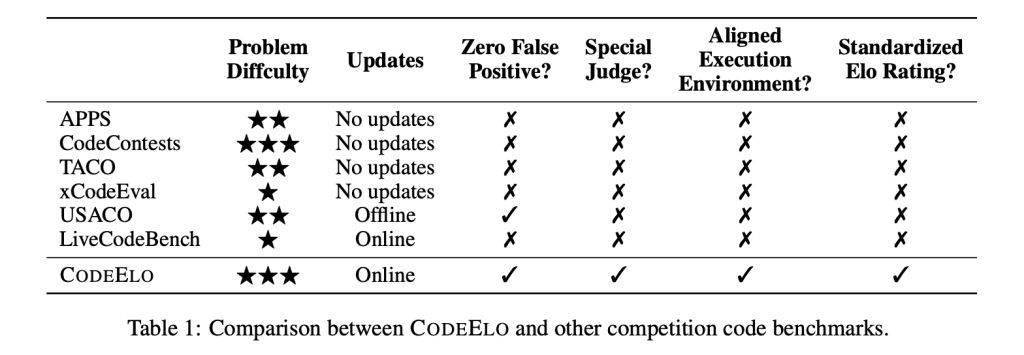
IT之家 1 月 4 日消息,阿里通义千问 Qwen 最新推出 CodeElo 基准测试,通过和人类程序员对比的 Elo 评级系统,来评估大语言模型(LLM)的编程水平。 项目背景 大语言模型的 AI 场景应用之一,就是生成、补全代码,只是现阶段评估编程真实能力方面存在诸多挑战。 包括 LiveCodeBench 和 USACO 在内的现有基准测试均存在局限性,缺乏健壮的私有测试用例,不支持专门的判断系统,并且经常使用不一致的执行环境。 CodeElo:借力 CodeForces,打造更精准的 LLM 评估体系 IT之家注:Qwen 研究团队为了解决这些挑战,推出了 CodeElo 基准测试,旨在利用与人类程序员比较的 Elo 评级系统,来评估 LLM 的编程竞赛水平。 CodeElo 的题目来自 CodeForces 平台,该平台以其严格的编程竞赛而闻名,通过直接向 CodeForces 平台提交解决方案,CodeElo 确保了评估的准确性,解决了误报等问题,并支持需要特殊评判机制的题目。此外,Elo 评级系统反映了人类的排名,可以有效比较 LLM 和人类参赛者的表现。 CodeElo 三大核心要素:全面、稳健、标准化 CodeElo 基于三个关键要素: 全面的问题选择: 题目按比赛分区、难度级别和算法标签进行分类,提供全面评估。 稳健的评估方法: 提交的代码在 CodeForces 平台上进行测试,利用其特殊评估机制确保准确判断,无需隐藏测试用例,并提供可靠反馈。 标准化的评级计算:Elo 评级系统评估代码的正确性,考虑问题难度,并对错误进行惩罚,激励高质量的解决方案,为评估编码模型提供了细致有效的工具。
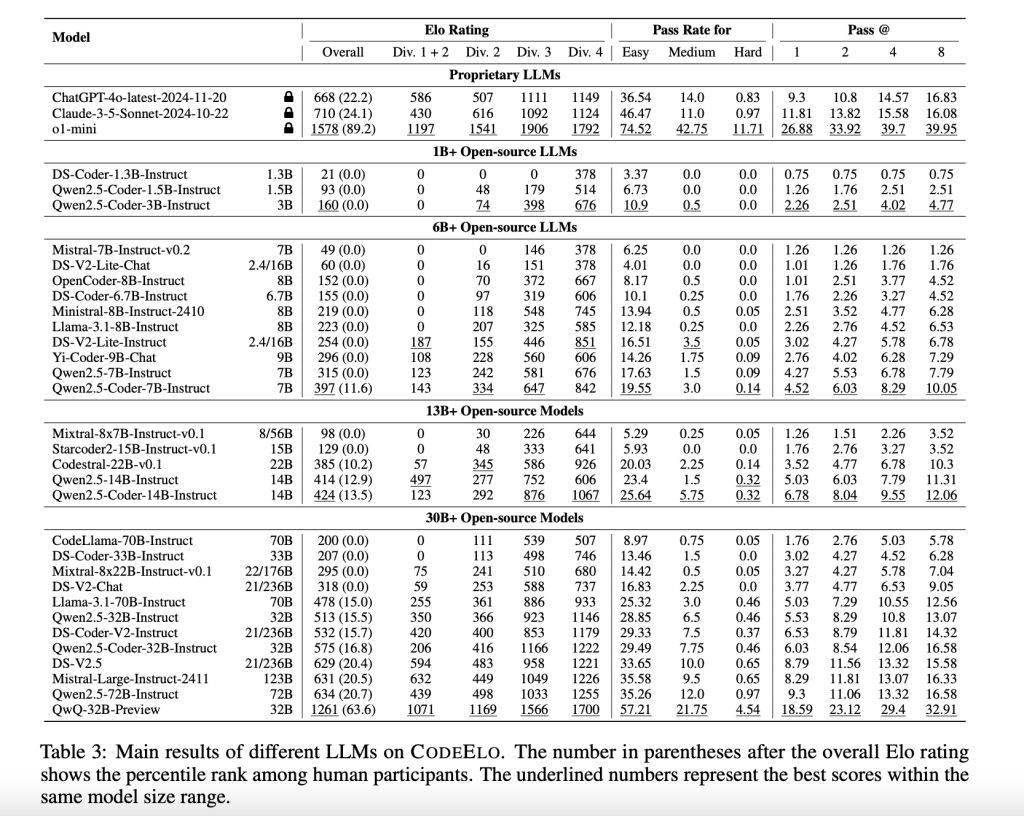
测试结果在对 30 个开源 LLM 和 3 个专有 LLM 进行测试后,OpenAI 的 o1-mini 模型表现最佳,Elo 评分为 1578,超过了 90% 的人类参与者;开源模型中,QwQ-32B-Preview 以 1261 分位居榜首。 然而,许多模型在解决简单问题时仍显吃力,通常排名在人类参与者的后 20%。分析显示,模型在数学和实现等类别表现出色,但在动态规划和树形算法方面存在不足。 此外,模型使用 C++ 编码时表现更佳,这与竞技程序员的偏好一致,这些结果突出了 LLM 需要改进的领域。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-1-5 00:18:18
发表于 2025-1-5 00:18:18
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





