爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册
x
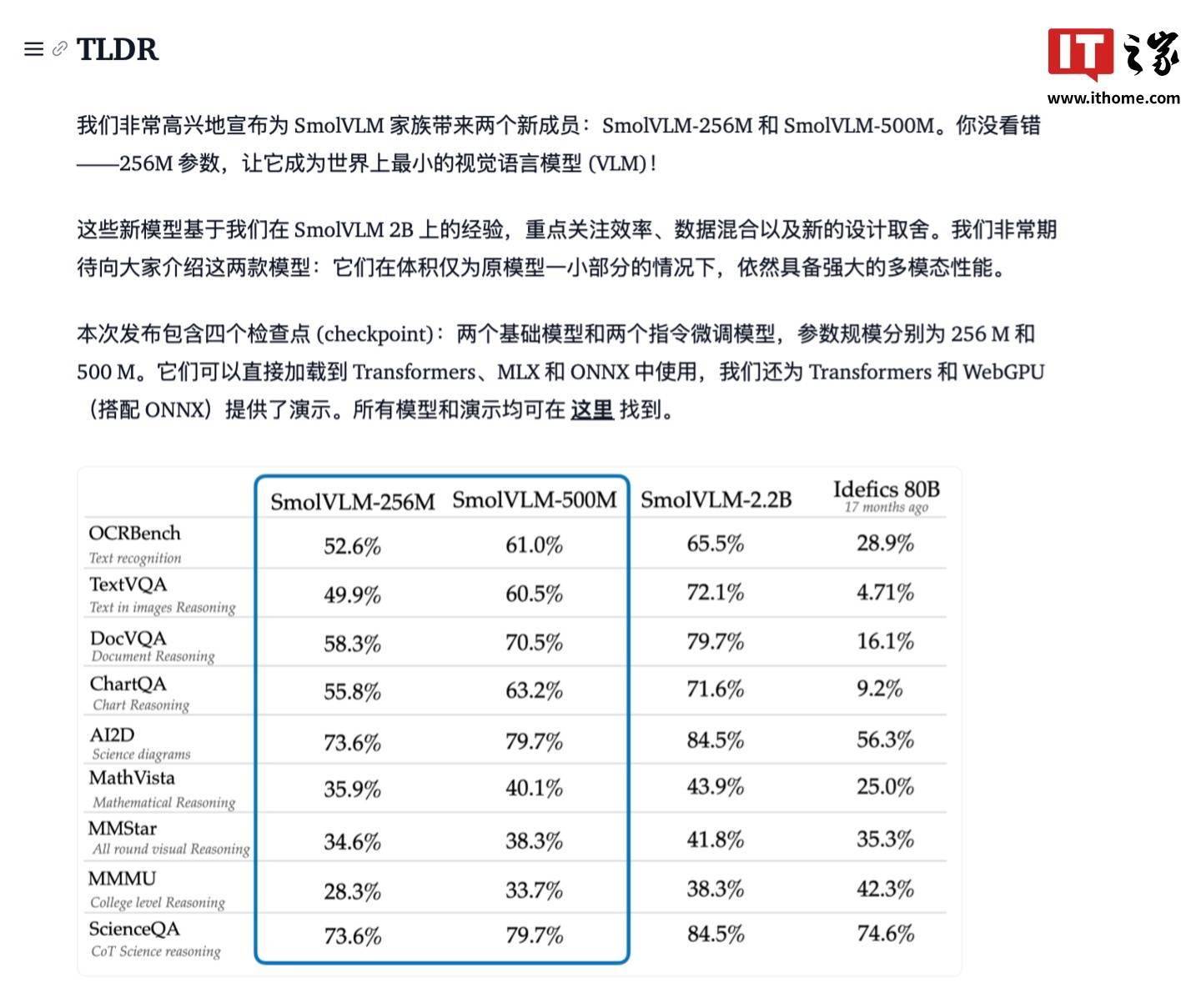
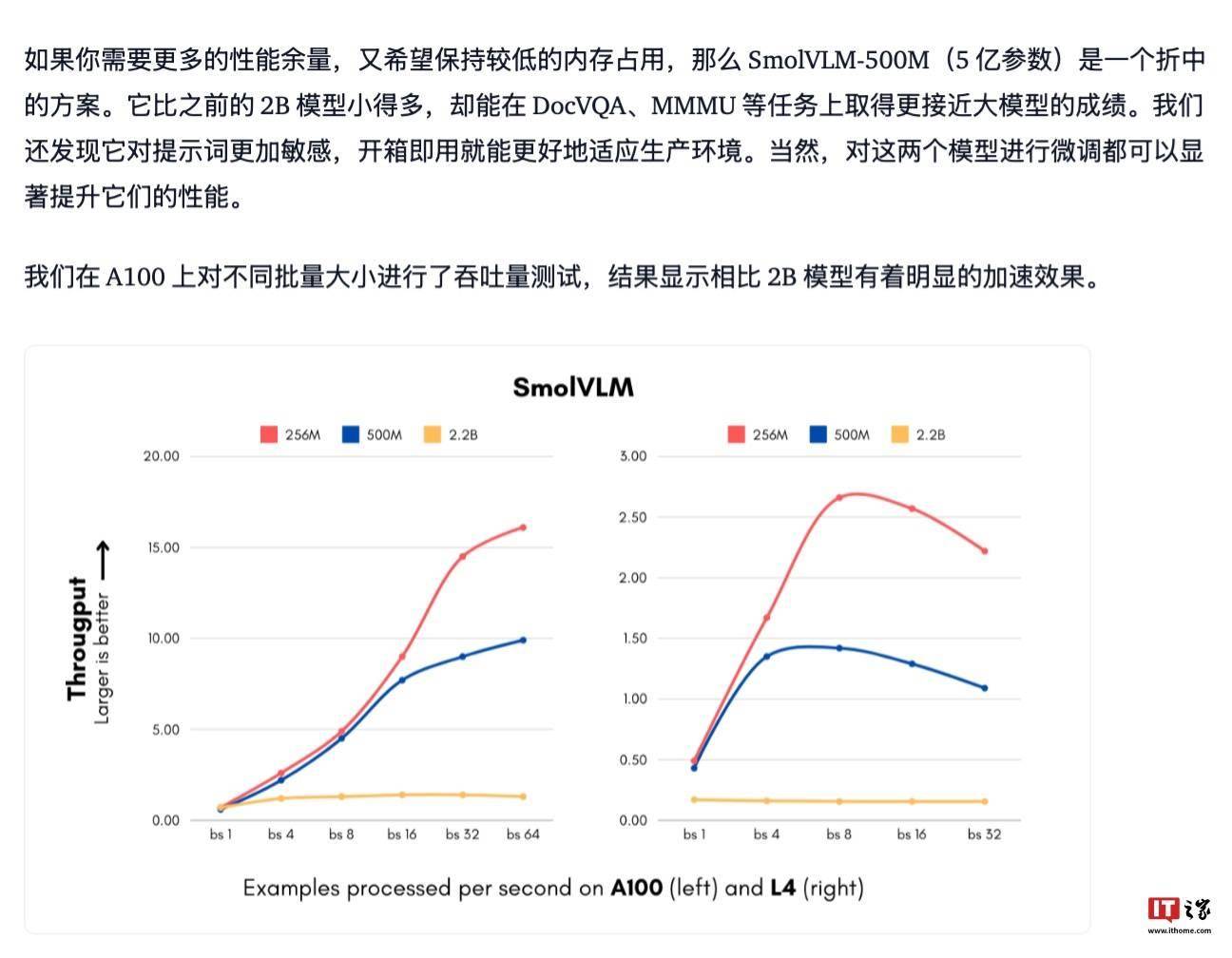
IT之家 1 月 26 日消息,Hugging Face 发布了两款全新多模态模型 SmolVLM-256M 和 SmolVLM-500M,其中 SmolVLM-256M 号称是世界上最小的视觉语言模型(Video Language Model)。 据悉,相应模型主要基于 Hugging Face 团队去年训练的 80B 参数模型蒸馏而成,号称在性能和资源需求之间实现了平衡,官方称 SmolVLM-256M / 500M 两款模型均可“开箱即用”,可以直接部署在 transformer MLX 和 ONNX 平台上。 具体技术层面,SmolVLM-256M / 500M 两款模型均采用 SigLIP 作为图片编码器,使用 SmolLM2 作为文本编码器。其中 SmolVLM-256M 是目前最小的多模态模型,可以接受任意序列的图片和文本输入并生成文字输出,该模型功能包括描述图片内容、为短视频生成字幕、处理 PDF 等。Hugging Face 称由于该模型整体轻巧,可在移动平台轻松运行,仅需不到 1GB 的 GPU 显存便可在单张图片上完成推理。 而 SmolVLM-500M 针对需要更高性能的场景而设计,Hugging Face 称相关模型非常适合部署在企业运营环境中,该模型推理单张图片仅需 1.23GB 的 GPU 显存,相对 SmolVLM-256M 虽然负载更大,但推理输出的内容更精准。 IT之家注意到,两款模型均采用 Apache 2.0 开源授权,研究团队提供了基于 transformer 和 WebGUI 的示例程序。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-1-27 22:53:33
发表于 2025-1-27 22:53:33

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





