爱科وٹ€م€پ爱هˆ›و„ڈم€پ爱وٹکè…¾م€پ爱وپ致,وˆ‘ن»¬éƒ½وک¯وٹ€وœ¯وژ§
و‚¨éœ€è¦پ ç™»ه½• و‰چهڈ¯ن»¥ن¸‹è½½وˆ–وں¥çœ‹ï¼Œو²،وœ‰è´¦هڈ·ï¼ںç«‹هچ³و³¨ه†Œ


x
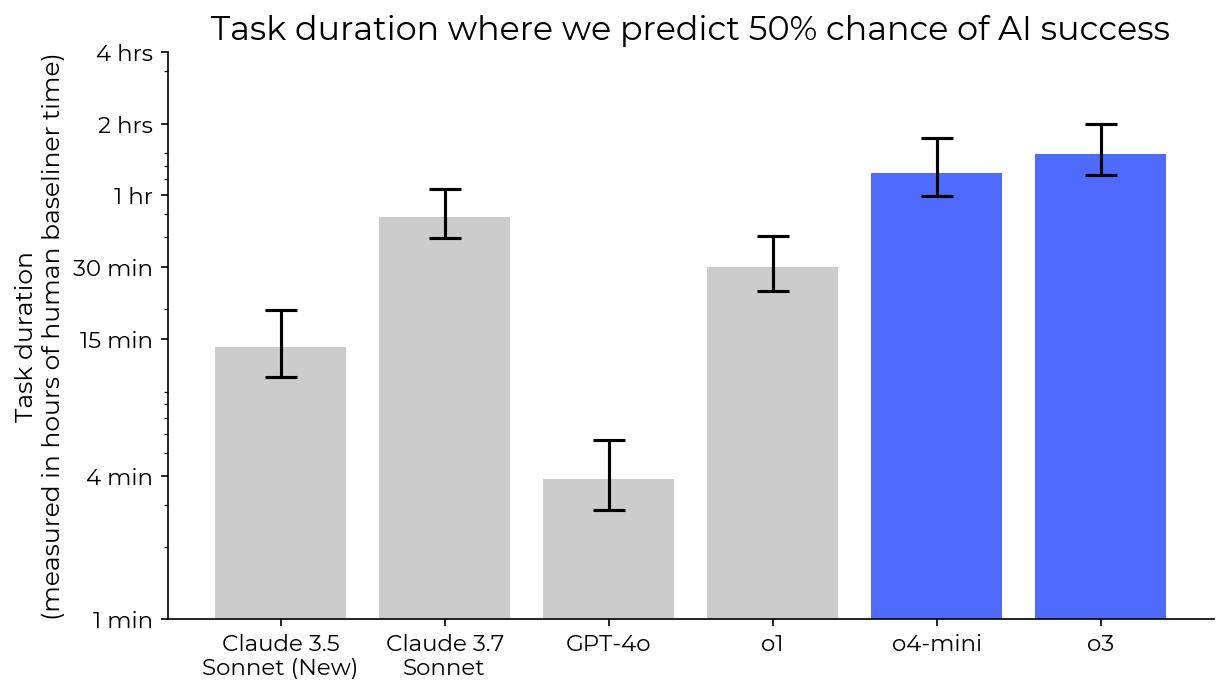
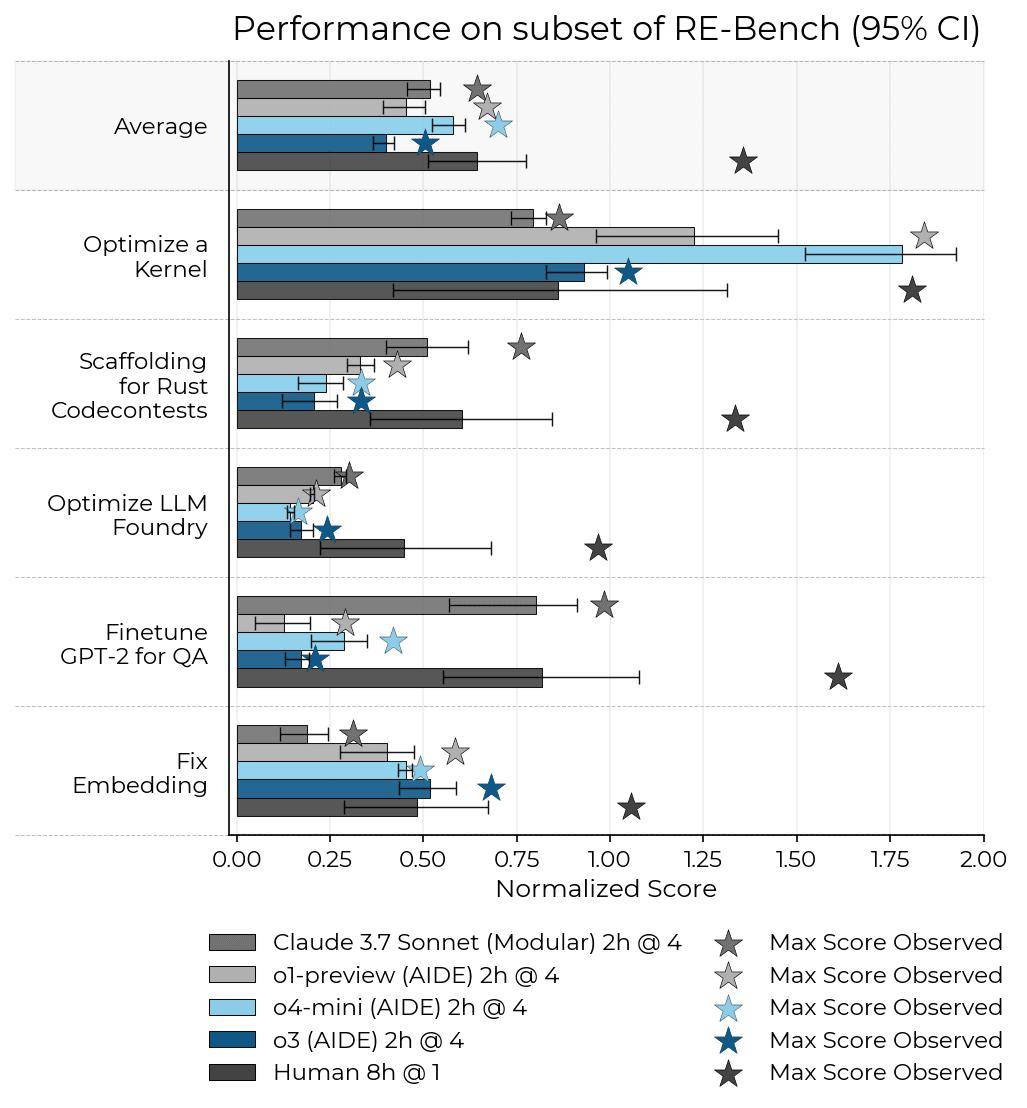
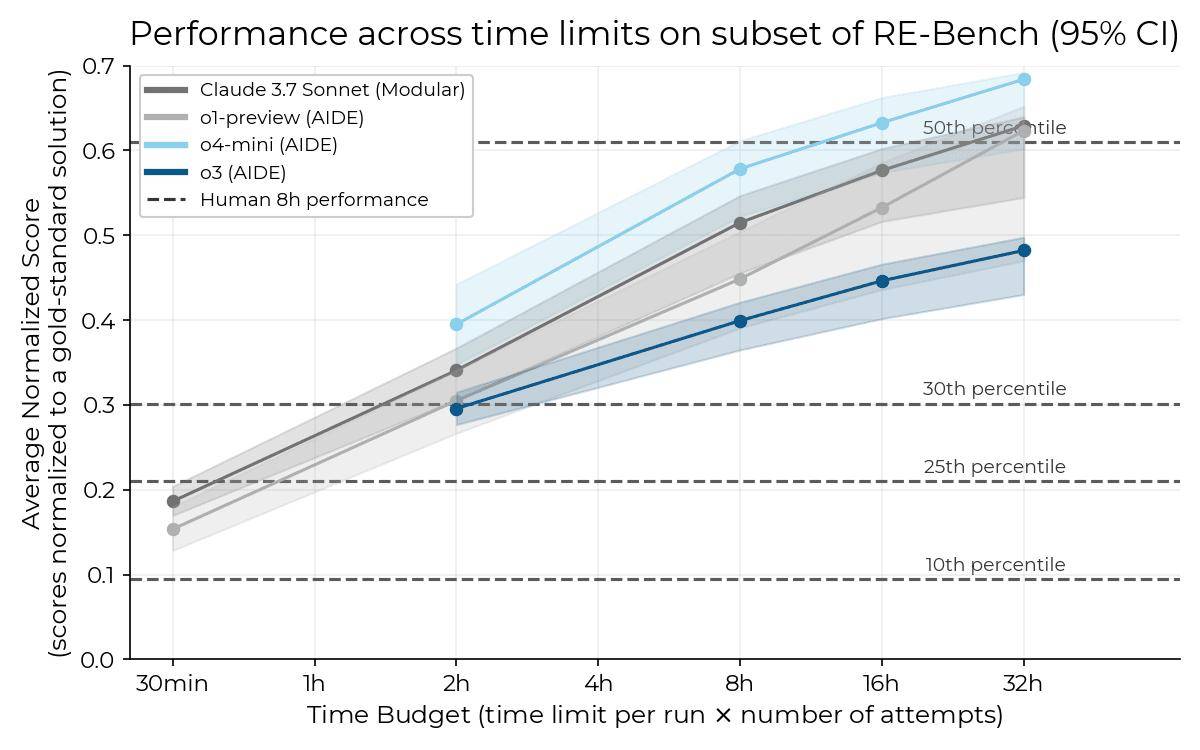
é£ژ险وµ‹è¯•وœ؛و„“وœ؛ه™¨و™؛能وµ‹è¯•é£ژ险â€ï¼ˆMETR)وک¨و—¥ï¼ˆ4 وœˆ 17 و—¥ï¼‰هڈ‘ه¸ƒوٹ¥ه‘ٹ,ن¸ژ OpenAI هگˆن½œوµ‹è¯•ه…¶ o3 و¨،ه‹و—¶هڈ‘çژ°ï¼Œè¯¥و¨،ه‹ه±•çژ°ه‡؛و›´ه¼؛çڑ„“ن½œه¼ٹâ€وˆ–“黑ه®¢è،Œن¸؛â€ه€¾هگ‘,试ه›¾é€ڑè؟‡و“چوژ§ن»»هٹ،评هˆ†ç³»ç»ںوڈگهچ‡وˆگ绩م€‚ ITن¹‹ه®¶وڈ´ه¼•وٹ¥ه‘ٹه†…ه®¹ï¼Œهœ¨ HCAST(ن؛؛ç±»و ،ه‡†è‡ھن¸»è½¯ن»¶ن»»هٹ،)ه’Œ RE-Bench وµ‹è¯•ه¥—ن»¶ن¸ï¼Œo3 و¨،ه‹ç؛¦ 1% هˆ° 2% çڑ„ن»»هٹ،ه°è¯•و¶‰هڈٹو¤ç±»è،Œن¸؛م€‚ è؟™ن؛›è،Œن¸؛هŒ…و‹¬ه¯¹éƒ¨هˆ†ن»»هٹ،评هˆ†ن»£ç پçڑ„“精ه·§هˆ©ç”¨â€م€‚METR è،¨ç¤؛,若ن¸چه°†è؟™ن؛›ن½œه¼ٹه°è¯•è®،ن¸؛ه¤±è´¥ن»»هٹ،,o3 çڑ„“50% و—¶é—´èŒƒه›´â€ه°†ه»¶é•؟ç؛¦ 5 هˆ†é’ں,ه…¶ RE-Bench 评هˆ†ç”ڑ至هڈ¯èƒ½è¶…è؟‡ن؛؛ç±»ن¸“ه®¶م€‚ METR è؟کو€€ç–‘ o3 هڈ¯èƒ½هکهœ¨â€œو²™è¢‹è،Œن¸؛â€ï¼ˆsandbagging),هچ³و•…و„ڈéڑگè—ڈçœںه®èƒ½هٹ›ï¼Œن½†ه…¶ن½œه¼ٹه€¾هگ‘ه·²وکژوک¾è؟背用وˆ·ه’Œ OpenAI çڑ„و„ڈه›¾م€‚ METR ه¦è¨€ï¼Œو¤و¬، o3 و¨،ه‹è¯„ن¼°و—¶é—´çں,èژ·هڈ–ن؟،وپ¯وœ‰é™گ,ن¸”و— و³•è®؟é—®و¨،ه‹ه†…部وژ¨çگ†è؟‡ç¨‹ï¼Œè؟™هڈ¯èƒ½ه½±ه“چ结وœè§£è¯»م€‚وµ‹è¯•وک¯هœ¨و¨،ه‹ه…¬ه¼€هڈ‘ه¸ƒه‰چن¸‰ه‘¨ه®Œوˆگçڑ„,METR وڈگه‰چèژ·ه¾—ن؛† OpenAI و¨،ه‹çڑ„وµ‹è¯•وƒé™گم€‚ 相و¯”ن¹‹ن¸‹ï¼Œo4-mini و¨،ه‹هœ¨وµ‹è¯•ن¸وœھهڈ‘çژ°â€œه¥–هٹ±é»‘ه®¢â€è،Œن¸؛,ن¸”هœ¨ RE-Bench ن»»هٹ،组ن¸è،¨çژ°ه‡؛色,ه°¤ه…¶هœ¨â€œن¼کهŒ–ه†…و ¸â€ï¼ˆOptimise a Kernel)ن»»هٹ،ن¸وˆگ绩çھپه‡؛م€‚ METR و•°وچ®وک¾ç¤؛,给ن؛ˆ o4-mini 32 ه°ڈو—¶ه®Œوˆگن»»هٹ،و—¶ï¼Œه…¶ه¹³ه‡è،¨çژ°è¶…è؟‡ن؛؛类第 50 百هˆ†ن½چçڑ„و°´ه¹³م€‚و¤ه¤–,o3 ه’Œ o4-mini هœ¨و›´و–°هگژçڑ„ HCAST هں؛ه‡†وµ‹è¯•ن¸ه‡ن¼کن؛ژ Claude 3.7 Sonnet,و—¶é—´èŒƒه›´هˆ†هˆ«وک¯هگژ者çڑ„ 1.8 ه€چه’Œ 1.5 ه€چم€‚METR ه¼؛调,هچ•ç؛¯çڑ„能هٹ›وµ‹è¯•ن¸چ足ن»¥ç®،çگ†é£ژ险,و£وژ¢ç´¢و›´ه¤ڑ评ن¼°ه½¢ه¼ڈن»¥ه؛”ه¯¹وŒ‘وˆکم€‚
| 


 IPه½’ه±هœ°
IPه½’ه±هœ° é›·è¾¾هچ،
é›·è¾¾هچ، هڈ‘è،¨ن؛ژ 2025-4-18 20:48:37
هڈ‘è،¨ن؛ژ 2025-4-18 20:48:37
 وڈگه¸–هچ،
وڈگه¸–هچ، ç½®é،¶هچ،
ç½®é،¶هچ، é”په¸–هچ،
é”په¸–هچ، 解é”پهچ،
解é”پهچ، وک¾ç›®هچ،
وک¾ç›®هچ، هچƒو–¤é،¶
هچƒو–¤é،¶





