爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
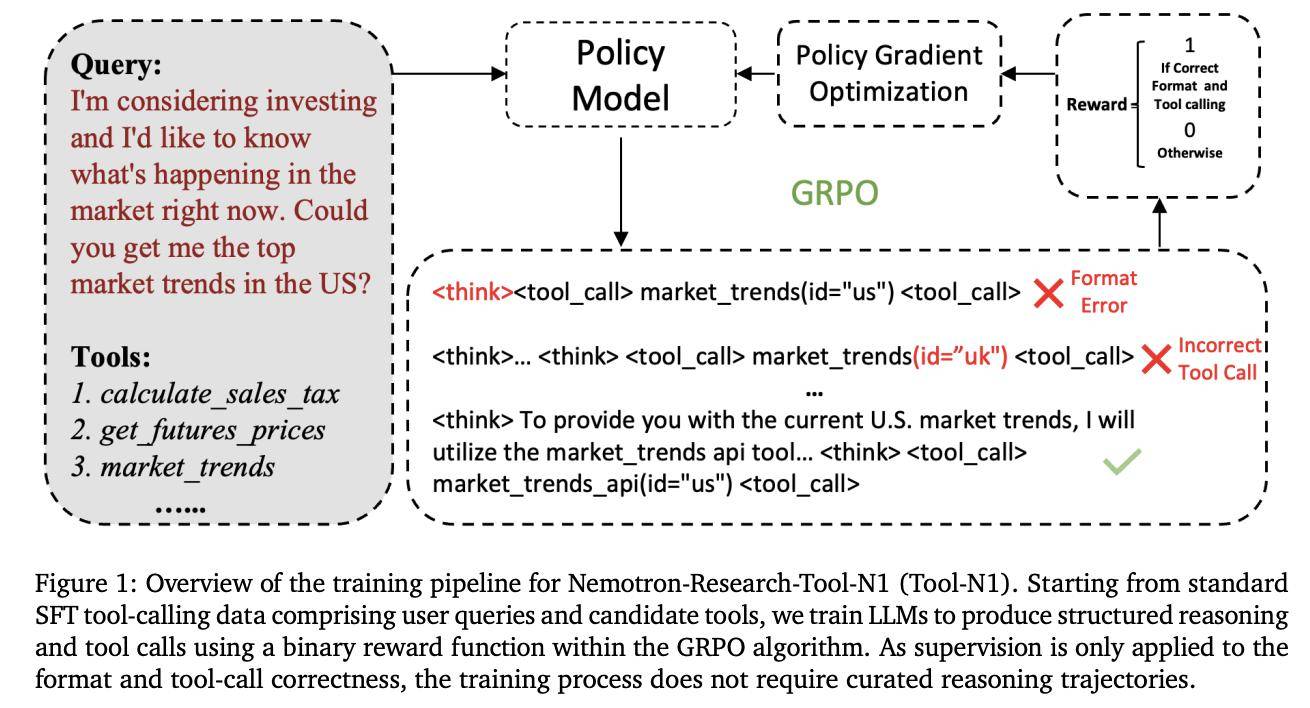
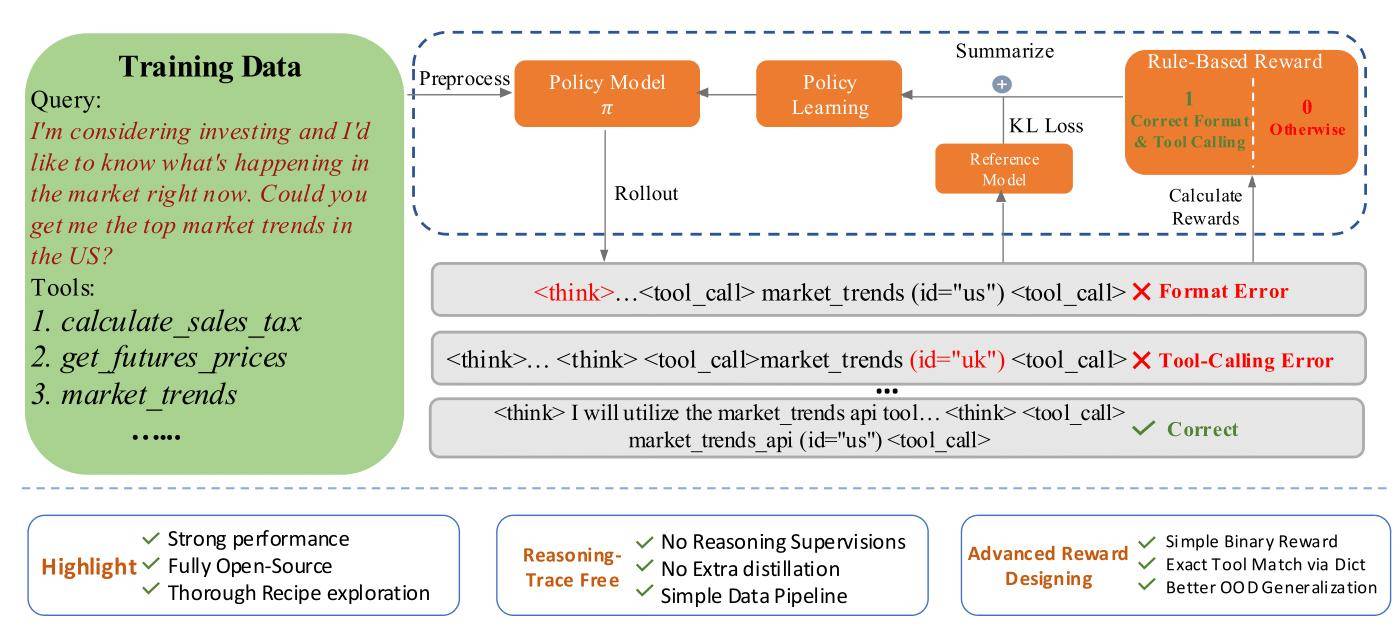
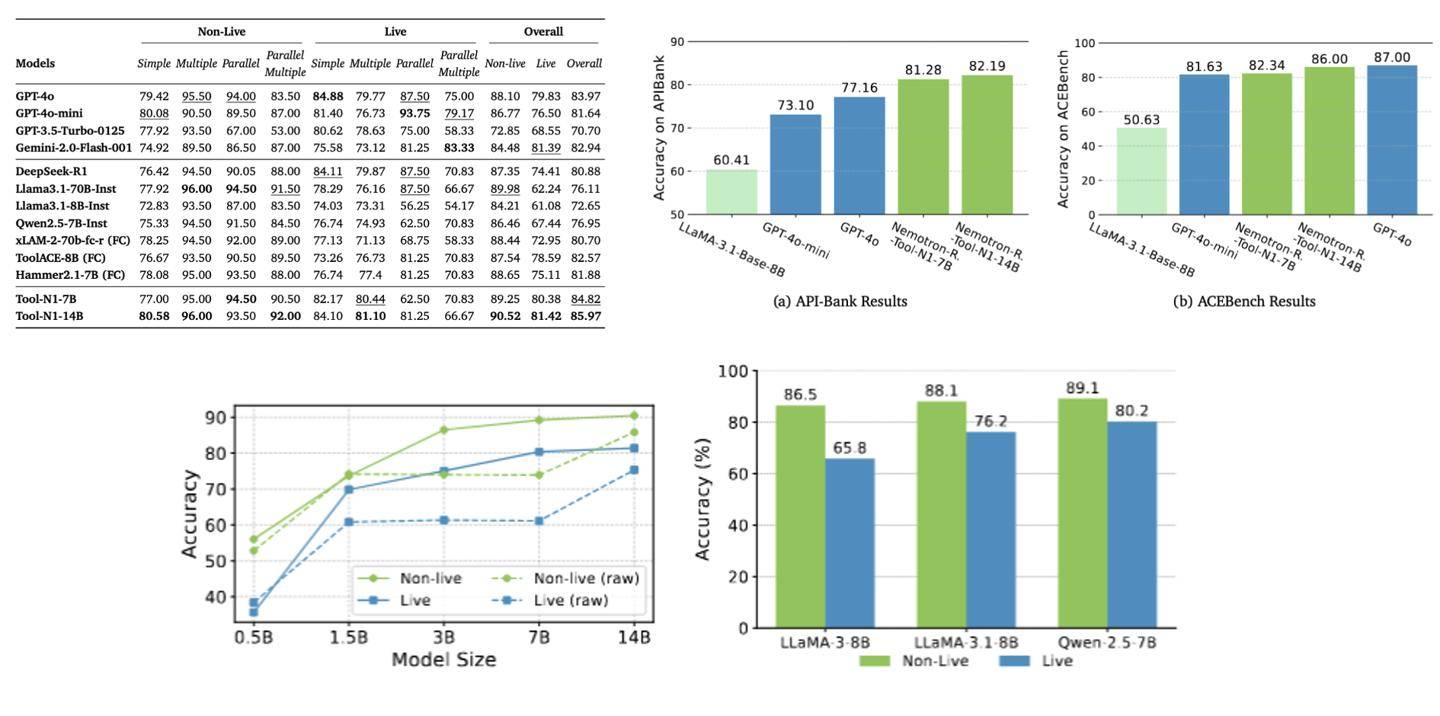
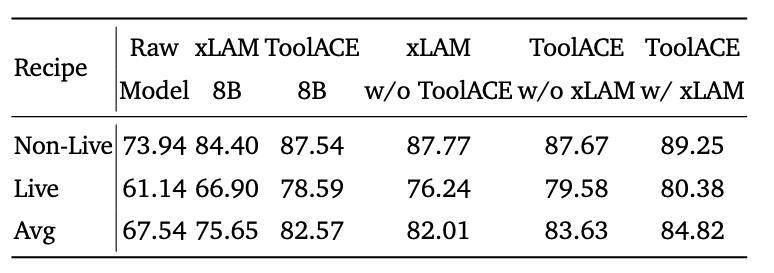
科技媒体 marktechpost 昨日(5 月 13 日)发布博文,报道称英伟达联合推出 Nemotron-Research-Tool-N1 系列模型,受 DeepSeek-R1 启发,采用新型强化学习(RL)范式,强化模型推理能力。 大型语言模型(LLMs)通过外部工具提升性能已成为热门趋势,这些工具帮助 LLMs 在搜索引擎、计算器、视觉工具和 Python 解释器等领域表现出色。但现有研究依赖合成数据集,无法捕捉明确的推理步骤,导致模型仅模仿表面模式,而非真正理解决策过程。 为了提升 LLMs 的工具使用能力,现有方法探索了多种策略。主要包括两方面:第一,数据集整理和模型优化。研究者创建大规模监督数据集,并应用监督微调(SFT)和直接偏好优化(DPO)强化学习等技术,将 LLMs 与外部工具整合,扩展其功能。 第二,改进推理过程。从传统的训练时扩展转向测试时复杂策略。早期方法依赖步骤级监督和学习奖励模型,指导推理轨迹。 这些方法虽有效,却仍受限于合成数据的不足。研究者指出,通过这些策略,LLMs 能处理单轮或多轮工具调用,但缺乏自主推理的深度。 英伟达联合宾夕法尼亚州立大学、华盛顿大学,组建专业团队,合作开发 Nemotron-Research-Tool-N1 系列,针对现有方法的局限性,借鉴 DeepSeek-R1 的成功,开发轻量级监督机制,专注于工具调用的结构有效性和功能正确性。 Nemotron-Research-Tool-N1 系列并非依赖显式标注的推理轨迹,而是采用二元奖励机制,让模型自主发展推理策略。 研究者统一处理了 xLAM 和 ToolACE 等数据集(提供单轮和多轮工具调用轨迹)的子集,并设计了轻量级提示模板,指导工具生成过程。 该模板使用 ... 标签明确指示中间推理,并用 < tool_call>... 标签封装工具调用,这样避免了过度拟合特定提示模式。 主干模型为 Qwen2.5-7B / 14B,并测试了 LLaMA 系列变体,以评估泛化能力。在 BFCL 基准测试中,Nemotron-Research-Tool-N1-7B/ 14B 模型表现出色,超越了 GPT-4o 等封闭源模型,以及 xLAM-2-70B 和 ToolACE-8B 等专用微调模型。 与相同数据源的 SFT 基准相比,该模型优势明显,证明了 RL 方法的有效性。在 API-Bank 基准上,Tool-N1-7B / 14B 的准确率分别比 GPT-4o 高出 4.12% 和 5.03%。这些结果验证了新方法的潜力,帮助 LLMs 更自主地生成推理策略。研究者总结认为,这标志着从传统 SFT 向 RL 范式的转变。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-5-14 20:00:50
发表于 2025-5-14 20:00:50

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





