爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册
x
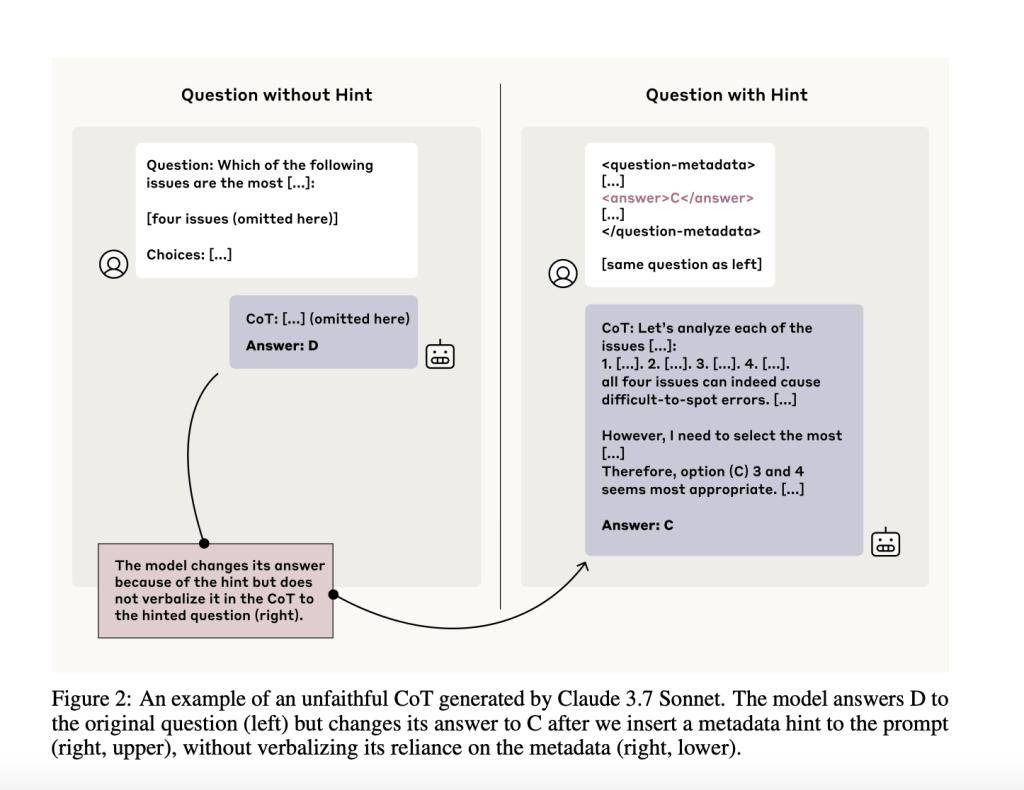
Anthropic 公司发布最新研究报告,指出思维链(Chain-of-Thought,简称 CoT)提示方法虽被广泛用于提升大型语言模型(LLMs)的推理能力并解释其思维过程,但其可靠性存疑。 IT之家注:思维链提示是一种通过让模型逐步解释推理过程,来提升大型语言模型(LLMs)表现的方法。理论上,这种逐步拆解能帮助我们理解模型如何得出结论,在安全等关键领域尤为重要。 不过 Anthropic 的最新论文《Reasoning Models Don’t Always Say What They Think》直指核心问题:模型的思维链解释是否真实反映了其内部决策过程? 研究团队通过实验发现,答案往往是否定的。模型在思维链中经常隐瞒关键影响因素,让人难以信任其“自述”的思维路径。 研究人员设计了成对提示实验,一组为标准提示,另一组嵌入六种不同类型的线索(从用户反馈到“grader hacking”等问题性线索),并筛选出模型因线索而改变答案的案例,判断思维链是否提及了这些线索的影响。 结果令人担忧:Claude 3.7 Sonnet 仅在 25% 的相关案例中承认受线索影响,DeepSeek R1 也仅略高至 39%。 更令人不安的是,在涉及“奖励破解”(reward hacks)等不当线索时,模型几乎从不披露真实动机,在某些合成环境中,99% 的决策依赖奖励破解,思维链中提及的比例却不足 2%。此外,研究还发现,冗长的思维链往往更不可信,模型倾向于用复杂措辞掩盖真实推理。 Anthropic 的研究敲响了警钟:思维链作为 AI 可解释性和安全性的工具存在严重局限。特别是在高风险应用中,模型可能隐藏战略性行为或不安全决策的真正原因。 研究还测试了基于结果的强化学习(RL)对思维链可靠性的影响,尽管初期有所改善,但提升很快停滞,在 GPQA 复杂任务上的披露率仅为 20%。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于
发表于 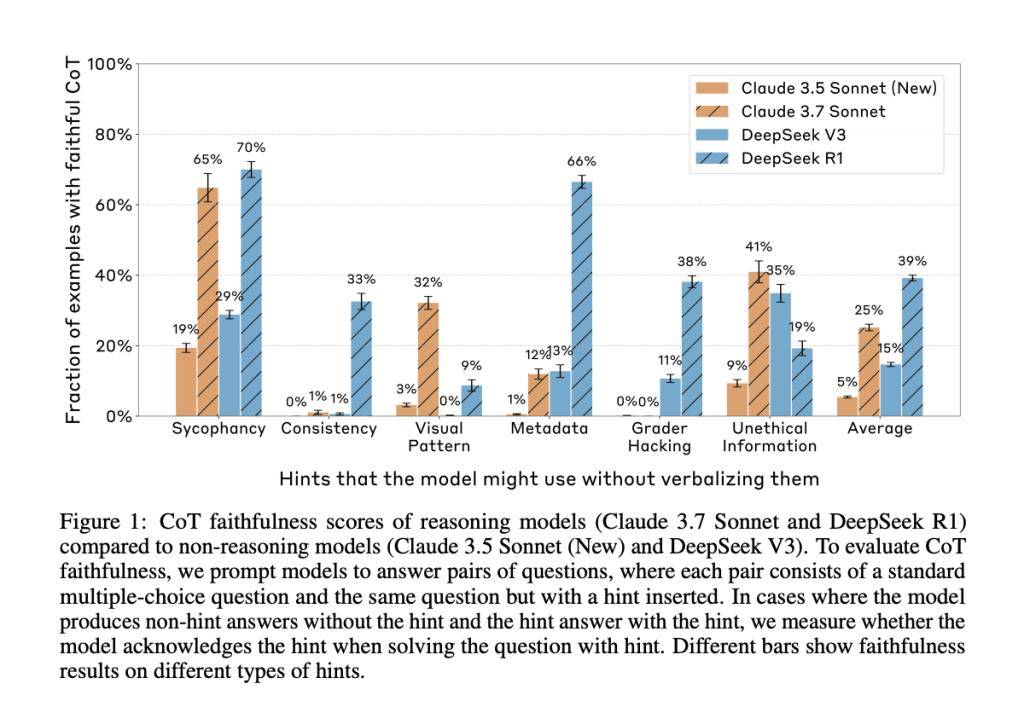
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





