爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册
x
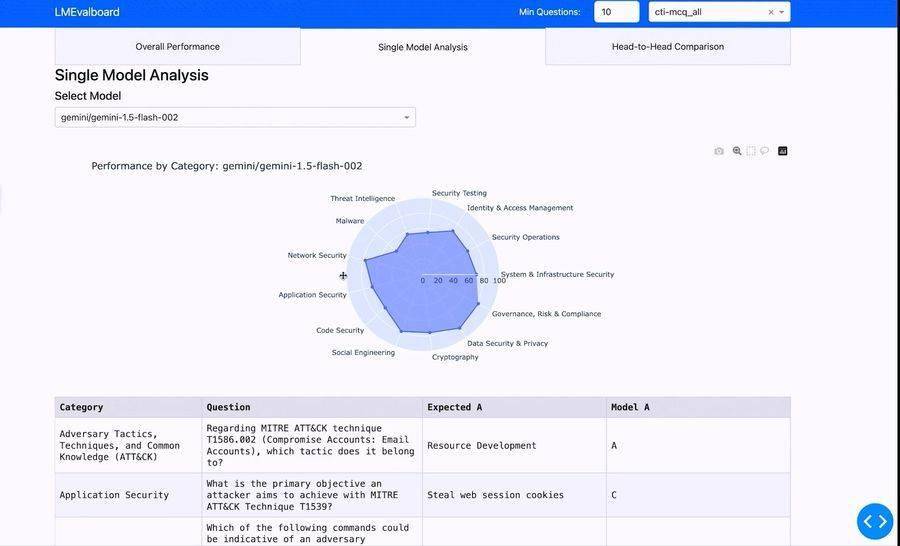
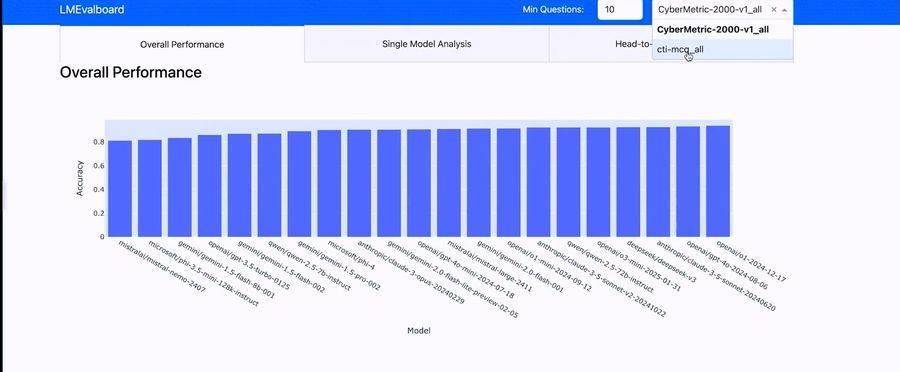
科技媒体 The Decoder 昨日(5 月 26 日)发布博文,报道称谷歌推出开源框架 LMEval,为大语言模型和多模态模型提供标准化的评测工具。 评测新型 AI 模型一直是个难题。不同供应商使用各自的 API、数据格式和基准设置,导致跨模型比较耗时且复杂。 而谷歌最新推出的 LMEval 开源框架直击这一痛点,研究人员和开发者只需设置一次基准,就能展开标准化的评测流程,大幅简化了评测工作,节省了时间和资源。 LMEval 还通过 LiteLLM 框架抹平了 Google、OpenAI、Anthropic、Ollama 和 Hugging Face 等平台之间的接口差异,确保测试跨平台无缝运行。 LMEval 不仅支持文本评测,还涵盖图像和代码等领域的基准测试,且新输入格式可轻松扩展,框架支持是非题、多选题和自由文本生成等多种评估类型。同时,该框架能识别模型采用的“规避策略”,即故意给出模糊回答以避免生成有风险内容。 Google 还引入了 Giskard 安全评分,展示模型规避有害内容的表现,百分比越高代表安全性越强。测试结果存储在自加密的 SQLite 数据库中,确保数据本地化且不会被搜索引擎索引,兼顾了隐私与便捷。 LMEval 具备增量评估功能,无需在新增模型或问题时重新运行整个测试,仅执行必要的新增测试即可,并采用多线程引擎并行处理多项计算,有效降低了计算成本和时间消耗。 谷歌还开发了 LMEvalboard 可视化工具,通过雷达图展示模型在不同类别中的表现。用户可深入查看具体任务,精准定位模型错误,并直接比较多个模型在特定问题上的差异,图形化展示一目了然。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-5-27 21:48:26
发表于 2025-5-27 21:48:26
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





