爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册
x
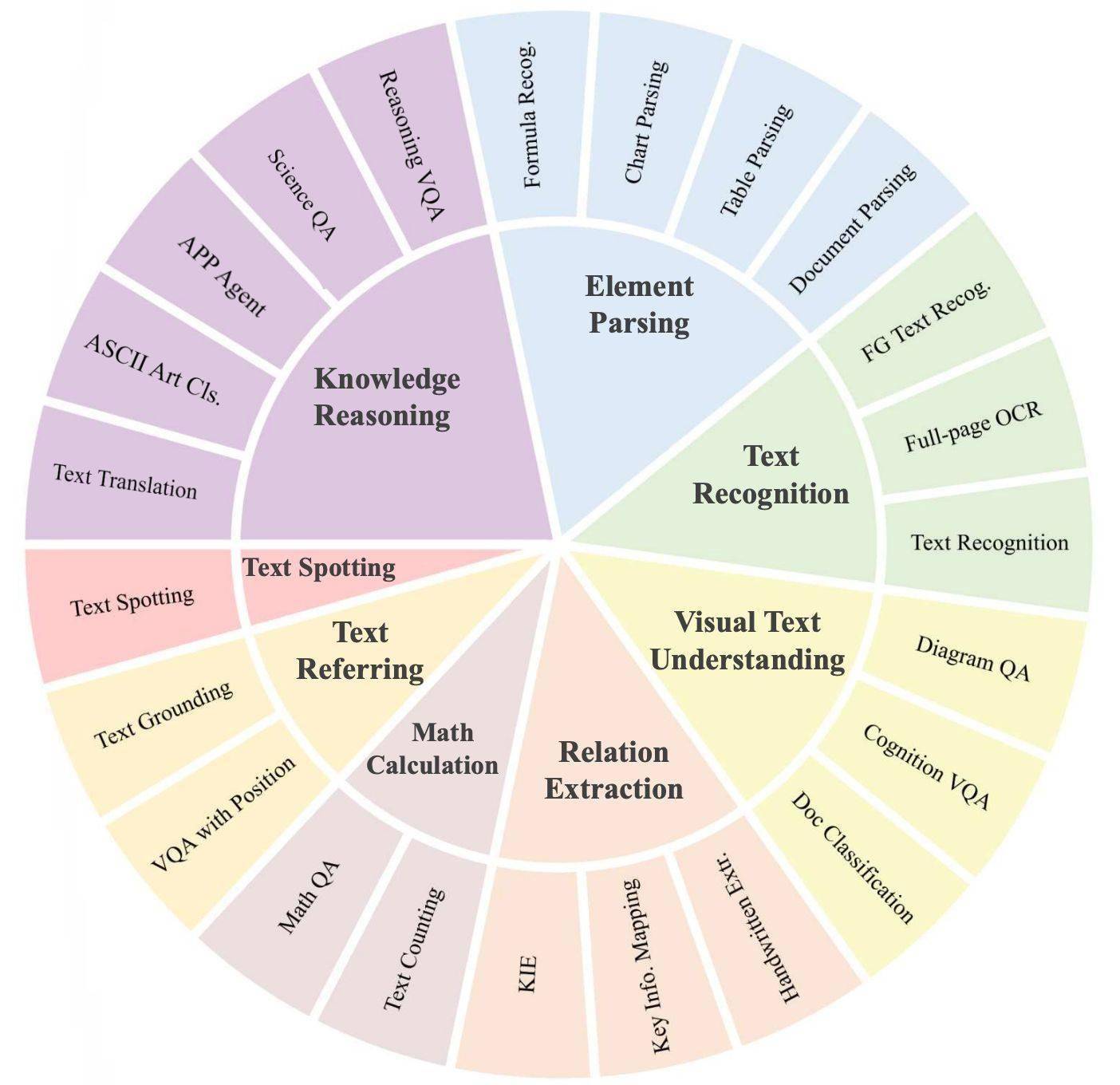
科技媒体 marktechpost 昨日(6 月 4 日)发布博文,报道称英伟达(Nvidia)针对高效、精准地处理文档级理解任务,推出 Llama Nemotron Nano VL 视觉-语言模型(VLM)。 Llama Nemotron Nano VL 基于 Llama 3.1 架构,融合了 CRadioV2-H 视觉编码器和 Llama 3.1 8B 指令微调语言模型,能同时处理多页文档中的视觉和文本元素,支持最长 16K 的上下文长度,覆盖图像和文本序列。 模型通过投影层和旋转位置编码实现视觉-文本对齐,优化了 token 效率,特别适合长篇多模态任务,无论是多图像输入还是复杂文本解析,它都能游刃有余。 该模型的训练分为三个阶段:首先,利用商业图像和视频数据集进行交错式图文预训练;其次,通过多模态指令微调提升交互式提示能力;最后,重新混合纯文本指令数据以优化在标准语言模型基准上的表现。 训练采用英伟达的 Megatron-LLM 框架和 Energon 数据加载器,依托 A100 和 H100 GPU 集群完成。在 OCRBench v2 基准测试中,该模型在 OCR、表格解析和图表推理等任务上取得领先精度,尤其在结构化数据提取(如表格和键值对)及布局相关问题解答中表现突出,媲美更大规模模型。 部署方面,Llama Nemotron Nano VL 设计灵活,支持服务器和边缘推理场景。英伟达提供了 4-bit 量化版本(AWQ),结合 TinyChat 和 TensorRT-LLM 实现高效推理,兼容 Jetson Orin 等受限环境。 模型还支持 Modular NIM(NVIDIA 推理微服务)、ONNX 和 TensorRT 导出,此外英伟达通过预计算视觉嵌入选项,进一步降低静态图像文档处理的延迟,为企业应用提供了实用解决方案。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于
发表于 

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶






