爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
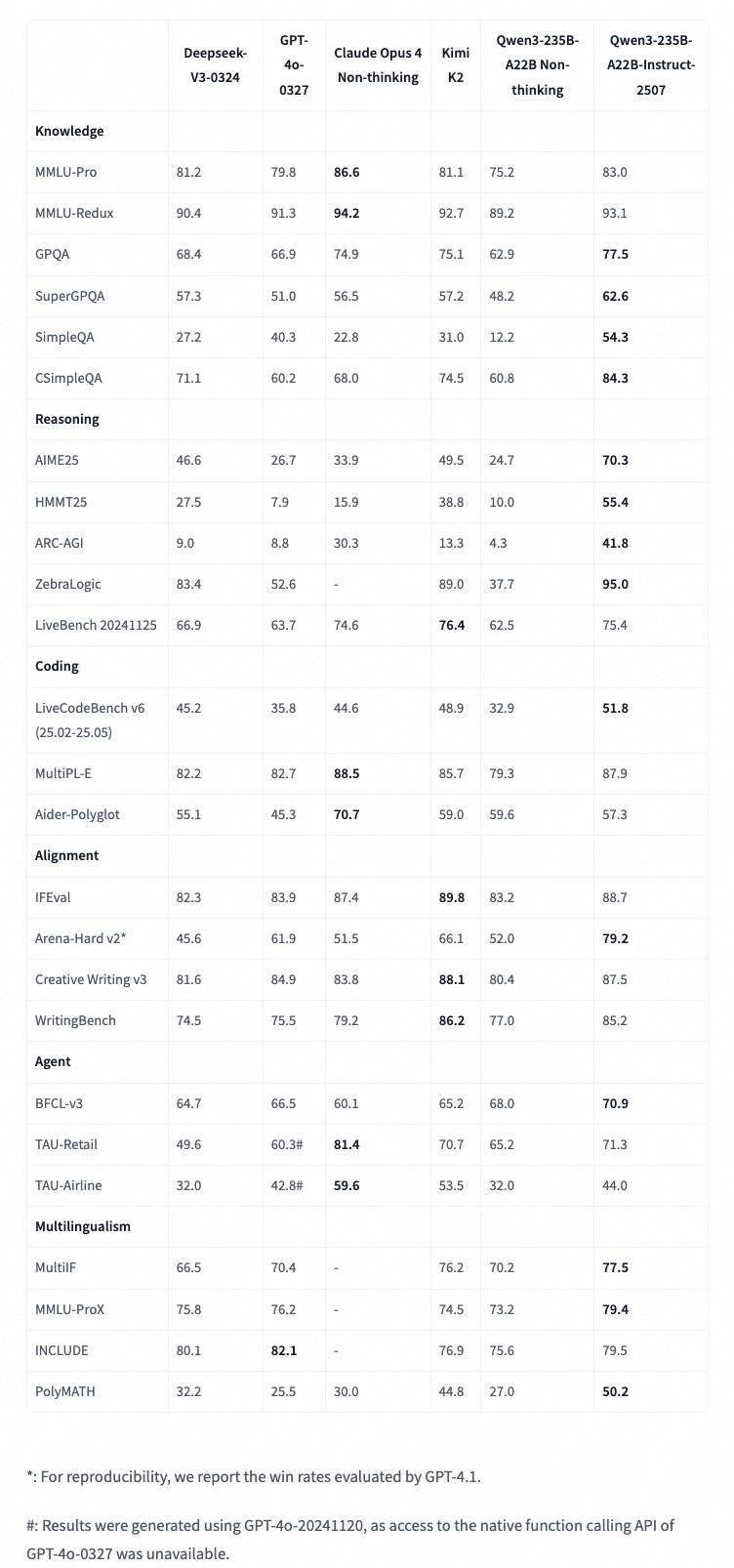
阿里云今天更新了旗舰版 Qwen3 模型,推出 Qwen3-235B-A22B-FP8 非思考模式(Non-thinking)的更新版本,命名为 Qwen3-235B-A22B-Instruct-2507-FP8。 阿里云表示,在经过与社区沟通和深思熟虑后,决定停止使用混合思考模式,转为分别训练 Instruct 和 Thinking 模型,以获得最佳质量。 据介绍,新的 Qwen3 模型通用能力显著提升,包括指令遵循、逻辑推理、文本理解、数学、科学、编程及工具使用等方面,在 GQPA(知识)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(人类偏好对齐)、BFCL(Agent 能力)等众多测评中表现出色,超过 Kimi-K2、DeepSeek-V3 等顶级开源模型以及 Claude-Opus4-Non-thinking 等领先闭源模型。 模型概述 FP8 版本的 Qwen3-235B-A22B-Instruct-2507具有以下功能特点: - 类型:因果语言模型 / 自回归语言模型
- 训练阶段:预训练与后训练
- 参数量:总共 235B,激活 22B
- 参数量(非嵌入):234B
- 层数:94
- 注意头数(GQA): Q 为 64,KV 为 4
- 专家数:128
- 激活专家数:8
- 上下文长度:原生支持 262,144。
阿里云表示,本次更新的 Qwen3 模型,还增强了以下关键性能: - 在多语言的长尾知识覆盖方面,模型取得显著进步。
- 在主观及开放性任务中,模型显著增强了对用户偏好的契合能力,能够提供更有用的回复,生成更高质量的文本。
- 长文本提升到 256K,上下文理解能力进一步增强。
目前,Qwen3 新模型已在魔搭社区和 HuggingFace 上开源更新,IT之家附官方地址:
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于
发表于 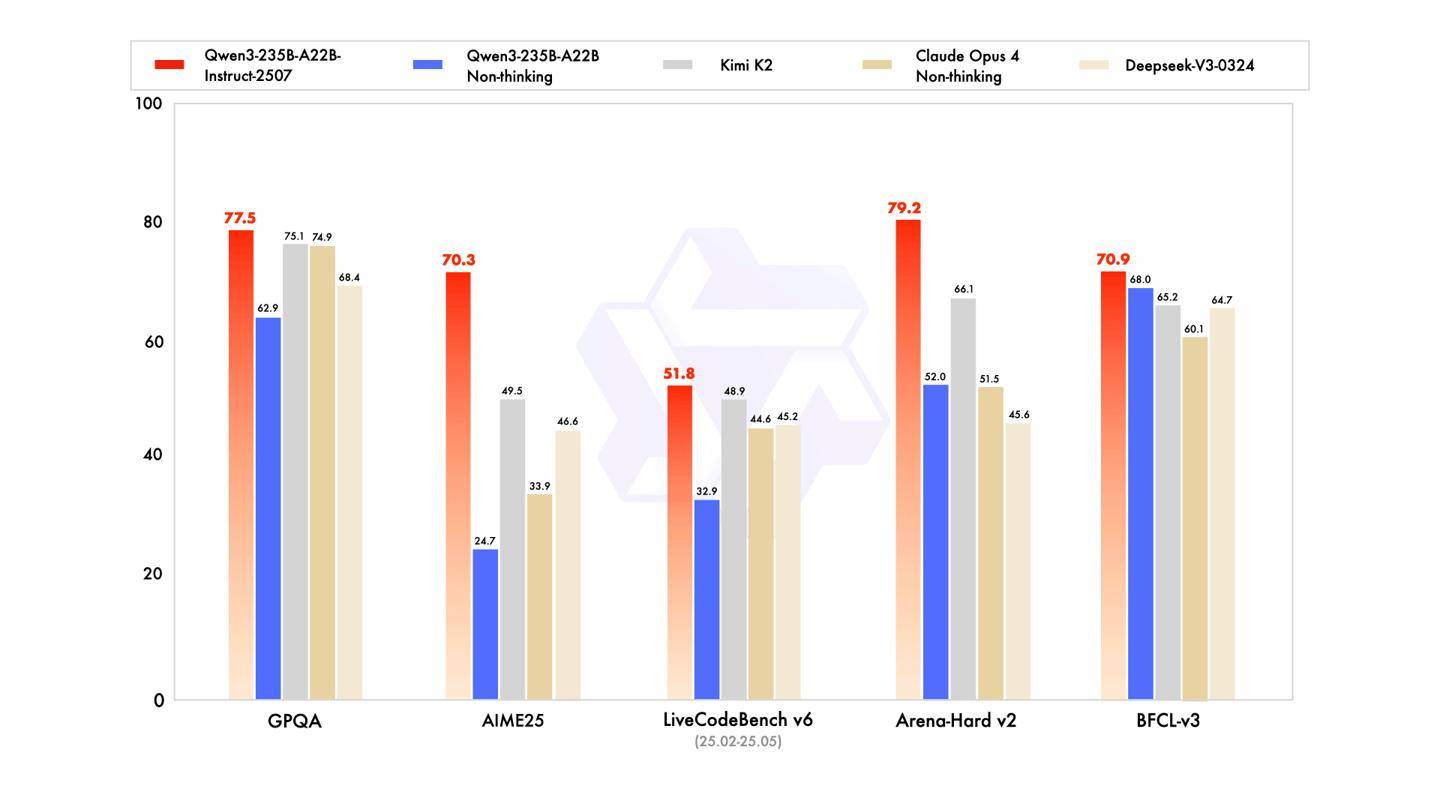
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





