爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册

x
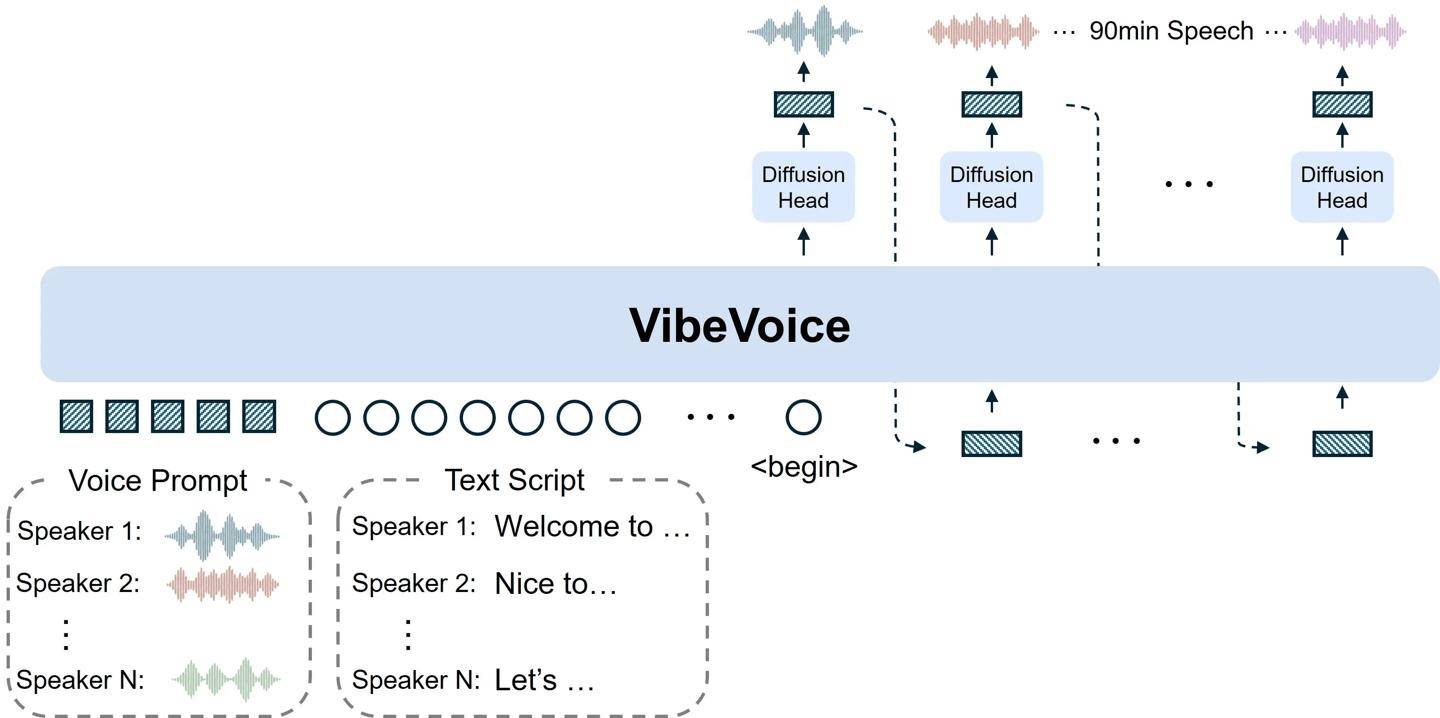
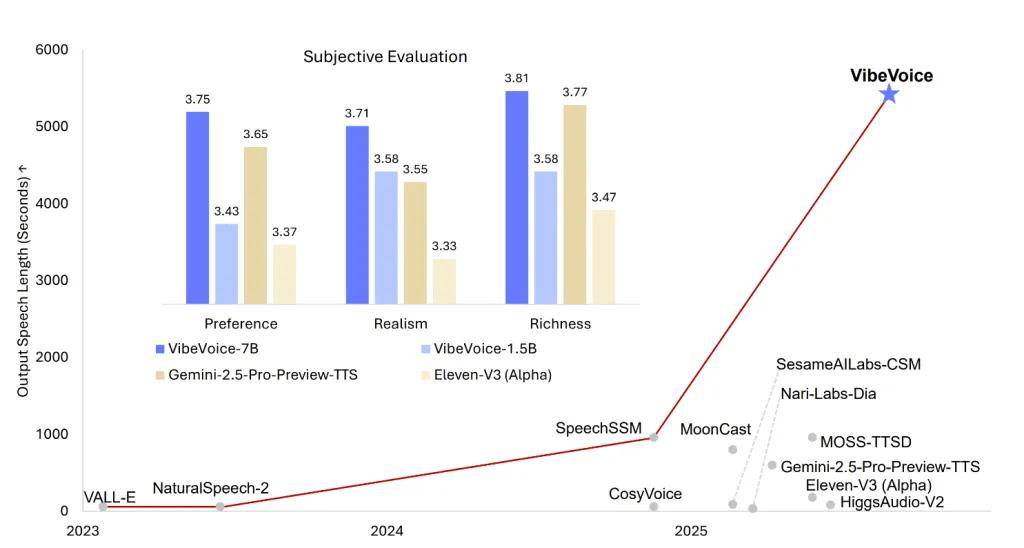
科技媒体 marktechpost 于 8 月 25 日发布博文,报道称微软发布开源文本转语音(TTS)模型 VibeVoice-1.5B,可一次生成最长 90 分钟、最多 4 位不同说话者的自然语音,并支持跨语言及歌声合成。 在架构方面,VibeVoice-1.5B 基于 1.5B 参数的 Qwen2.5 语言模型,结合声学(Acoustic)与语义(Semantic)双分词器(Tokenizer),以 7.5Hz 低帧率处理。 声学分词器使用 σ-VAE 结构,将 24kHz 原始音频压缩至 3200 分之一;语义分词器则通过语音识别代理任务训练,保留对话语义。解码端采用 1.23 亿参数的扩散解码器,结合分类器自由引导和 DPM-Solver,来提升音质与细节表现。 该模型为确保在长篇对话中保持语音连贯性与说话人一致性,在训练中逐步扩展上下文长度,从 4k 至 65k Tokens,其架构支持多说话者的轮流发言,模拟自然对话场景,且可在流式模式下生成长音频,为未来实时 TTS 奠定基础。 VibeVoice-1.5B 也有局限,目前仅支持英语与中文,其他语言可能出现不准确或不当内容;不支持说话人语音重叠,也无法生成背景音效或音乐。微软明确禁止将该模型用于声音冒充、虚假信息传播或绕过身份验证等用途,并提醒用户遵守法律并标明 AI 生成来源。 微软表示,该模型主要面向科研和开发者社区,适合播客制作、对话式 AI、语音内容生成等领域。未来将推出参数更大的 7B 版本,支持低延迟交互和更高保真度的实时合成,进一步拓展应用场景。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-8-27 20:26:45
发表于 2025-8-27 20:26:45
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶