爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
IT之家 5 月 7 日消息,腾讯混元(Tencent Hunyuan)携手加州大学洛杉矶分校(UCLA)、香港中文大学等学府,联合发布 OpenSearch-VL 开源多模态训练方案,通过强化学习(RL)技术,打造具备前沿能力的深度搜索智能体。 多模态搜索智能体指能够处理图像、文本等多种模态输入,并主动调用外部工具(如搜索引擎、图像处理工具)进行多步骤推理、证据验证与知识检索的智能体,旨在解决知识密集型的复杂视觉问答。 该报告昨日(5 月 6 日)在 arXiv 平台发表,介绍了 OpenSearch-VL 方案,用于训练前沿多模态深度搜索智能体。研究构建了高质量数据管道,通过维基百科路径采样与模糊实体重写减少检索捷径,产出 SearchVL-SFT-36k 等数据集。 研究团队指出,目前阻碍前沿多模态搜索智能体进化的最大瓶颈,在于高质量的训练数据。现有顶尖系统多由商业公司主导,其数据来源、过滤标准与工具使用轨迹均属私有,阻碍了先进能力的复现与系统性研究。 研究提出 OpenSearch-VL,提供从数据、工具到训练算法的完整开源方案。 在构建数据管道方面,OpenSearch-VL 提出利用维基百科的超链接图谱,执行多跳实体路径采样,将中间实体重写为模糊描述,并将锚点实体锚定至源图像,从而抑制单步检索捷径,鼓励智能体学习多跳搜索与推理行为。 管道产出 SearchVL-SFT-36k 数据集用于监督微调,平均每轨迹包含 6.3 次工具调用。同时,随机选取 10% 数据应用模糊、下采样等降质处理,配对增强工具,诱导“边思考边处理图像”的行为。 工具环境超越仅检索的智能体,统一文本搜索、图像搜索、OCR、裁剪、锐化、超分辨率与透视校正等功能。这允许智能体在查询外部知识前,先处理模糊、低分辨率或倾斜的视觉输入,实现主动感知与知识获取的结合。 实验显示,OpenSearch-VL-30B-A3B 模型将基线平均得分从 47.8 提升至 61.6,在 VDR、MMSearch 等基准上取得显著增益。消融实验验证了各组件贡献:移除源锚点锚定、模糊重写或分阶段过滤导致平均得分下降 8.2 至 11.5 点。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于
发表于 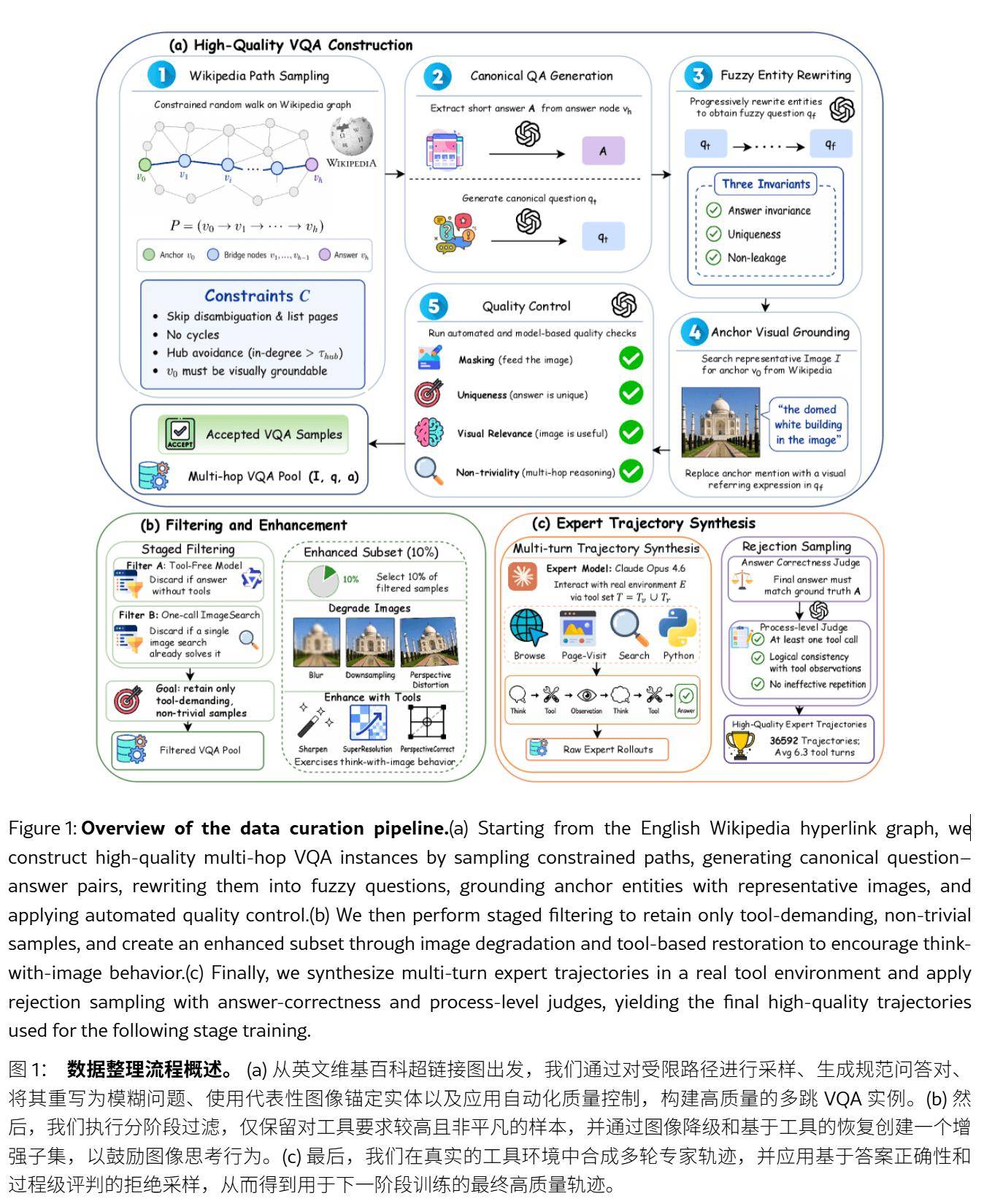

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





