您需要 登录 才可以下载或查看,没有账号?立即注册
使用道具 举报
罗蒙POLO衫39!骨传导耳机25!养
罗马仕三合一编织快充线7!露营
骆驼循环扇24!清凉油10个+风油
星鲨维D滴剂3盒56!灭蝇神器6!
玻璃水4瓶9 !小熊隔水电炖锅69
不锈钢菜刀7!木筷子2!双面菜板
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
APP|手机版|小黑屋|关于我们|联系我们|法律条款|技术知识分享平台
闽公网安备35020502000485号
闽ICP备2021002735号-2
GMT+8, 2025-5-11 06:01 , Processed in 0.171600 second(s), 8 queries , Redis On.
Powered by Discuz!
© 2006-2025 MyDigit.Net



 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-1-16 15:14:13
发表于 2025-1-16 15:14:13
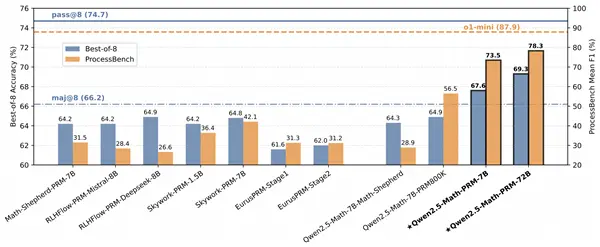
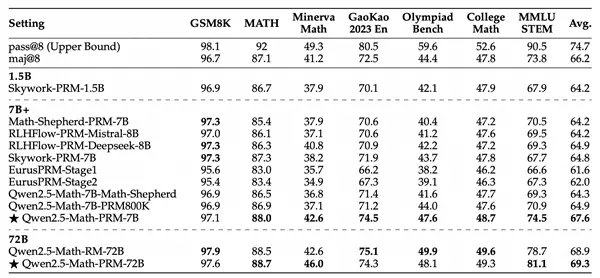
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





