爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
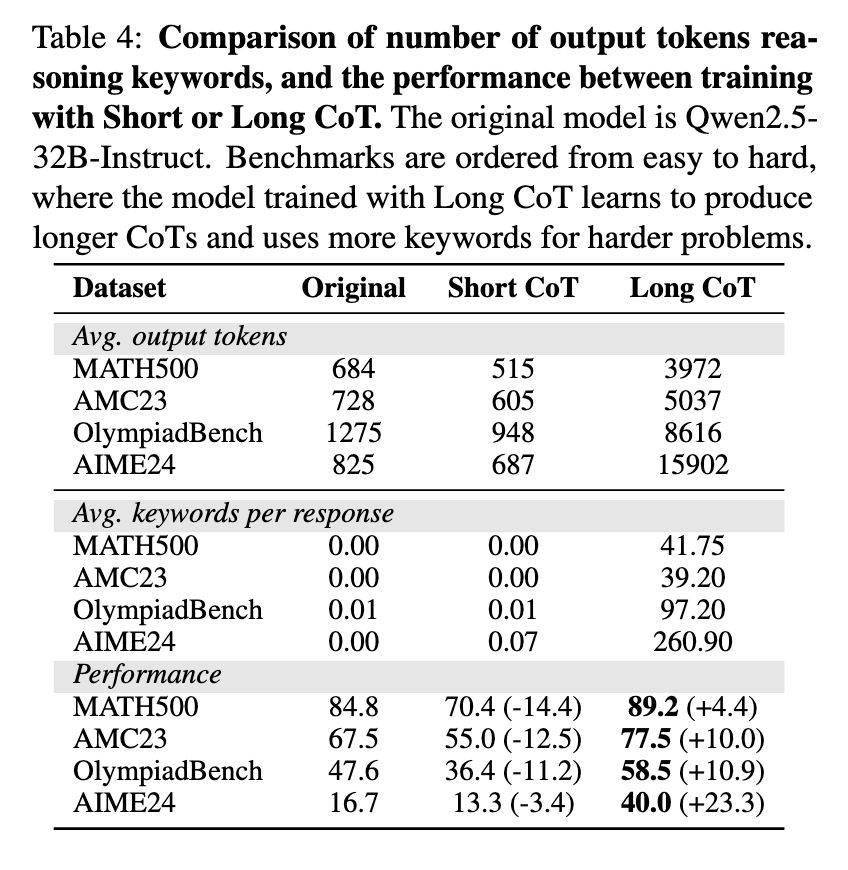
科技媒体 marktechpost (2 月 14 日)发布博文,报道称加州大学伯克利分校的研究团队提出了一种 AI 训练方法,仅需少量数据即可增强大语言模型(LLM)推理能力。 提升 LLM 推理能力的难点在于训练模型生成具有结构化自反思、验证和回溯的长链式思维(CoT)响应。现有模型的训练过程通常需要在大量数据集上进行昂贵的微调,且许多专有模型的训练方法并不公开。 研究团队提出了一种新的训练方法,仅使用 17000 个 CoT 示例,微调 Qwen2.5-32B-Instruct 模型,并结合了 SFT 和 LoRA 微调技术,强调优化推理步骤的结构完整性而非内容本身,通过改进逻辑一致性并最大限度地减少不必要的计算开销,从而显著提高了 LLM 的推理效率。 研究表明,在增强 LLM 推理性能方面,CoT 的结构起着至关重要的作用,改变训练数据的逻辑结构会显著影响模型的准确性,而修改单个推理步骤的影响则很小。 IT之家附上使用新方法后的测试效果如下: AIME 2024:准确率达到 56.7%,提升了 40.0 个百分点。 LiveCodeBench:得分 57.0%,提升了 8.1 个百分点。 Math-500:达到 90.8%,提升了 6.0 个百分点。 AMC 2023:达到 85.0%,提升了 17.5 个百分点。 OlympiadBench:达到 60.3%,提升了 12.7 个百分点。
这些结果表明,高效的微调技术可以使 LLM 在更少的数据需求下达到与 OpenAI 的 o1-preview 等专有模型相媲美的推理能力。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-2-16 02:23:31
发表于 2025-2-16 02:23:31


 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





