爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
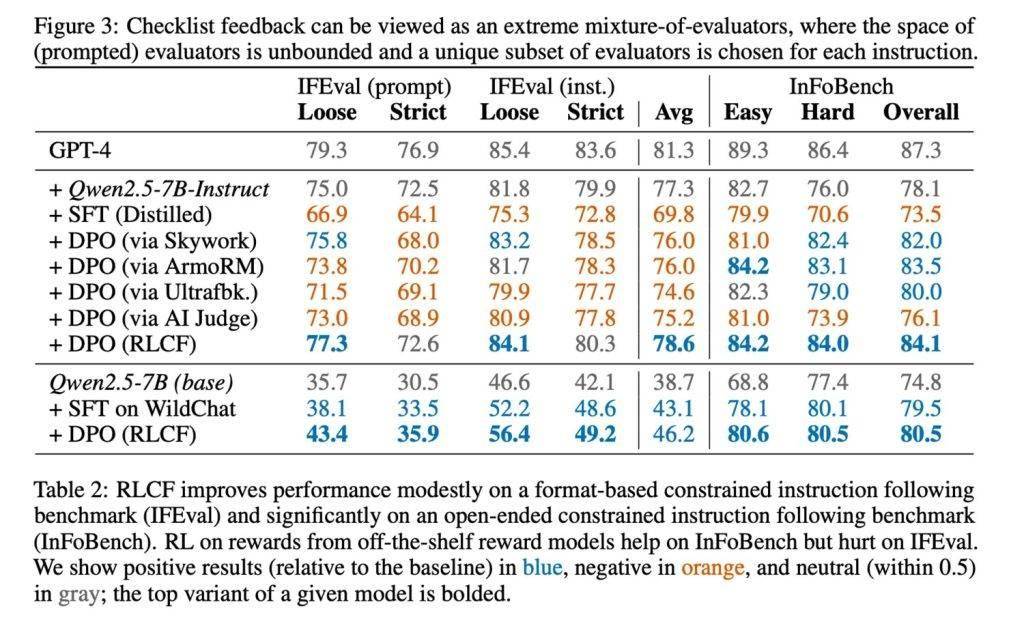
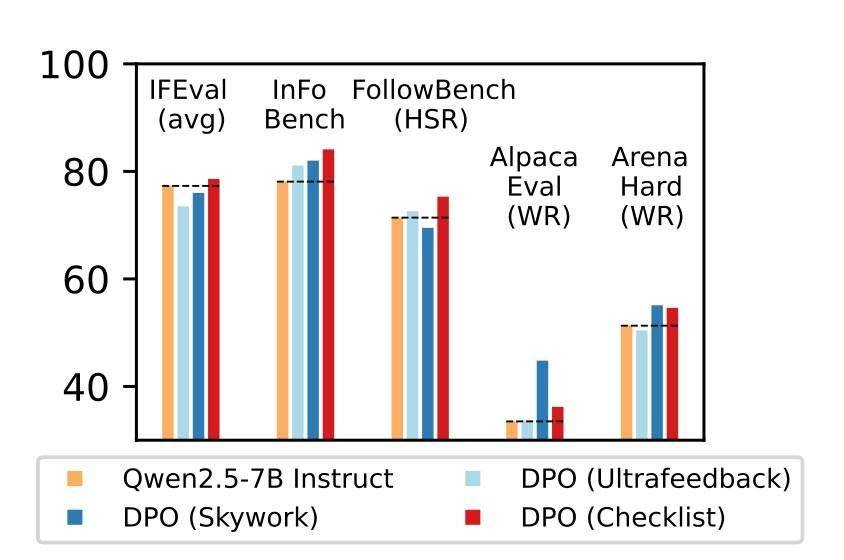
科技媒体 9to5Mac 昨日(8 月 25 日)发布博文,报道称苹果研究人员在最新论文中提出“基于清单反馈的强化学习”(RLCF)方法,用任务清单替代传统人类点赞 / 点踩评分,显著提升大语言模型(LLMs)执行复杂指令能力。 IT之家注:RLCF 的全称为 Reinforcement Learning from Checklist Feedback,不同于传统的“人类反馈强化学习”(RLHF)依赖人工点赞 / 点踩,RLCF 为每条用户指令生成具体的检查清单,并按 0-100 分逐项评分,用以指导模型优化。 研究团队在强指令跟随模型 Qwen2.5-7B-Instruct 上测试该方法,涵盖五个常用评测基准。结果显示,RLCF 是唯一在全部测试中均取得提升的方案: - FollowBench 硬性满意率提升 4 个百分点
- InFoBench 提高 6 点
- Arena-Hard 胜率增加 3 点
- 某些任务最高提升达 8.2%。
这表明清单反馈在复杂、多步骤需求的执行中效果显著。 清单的生成过程也颇具特色。团队利用更大规模的 Qwen2.5-72B-Instruct 模型,结合既有研究方法,为 13 万条指令生成了“WildChecklists”数据集。清单内容为明确的二元判断项,例如“是否翻译成西班牙语?”。随后,大模型对候选回答逐项打分,综合加权后作为小模型的训练奖励信号。 苹果研究者也坦言该方法存在局限。首先,它依赖更强模型作为评判者,这在资源受限场景下未必可行。其次,RLCF 专注于提升复杂指令执行能力,并非设计用于安全对齐,因此不能替代安全性评估与调优。对于其他任务类型,该方法的适用性仍需进一步验证。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于
发表于 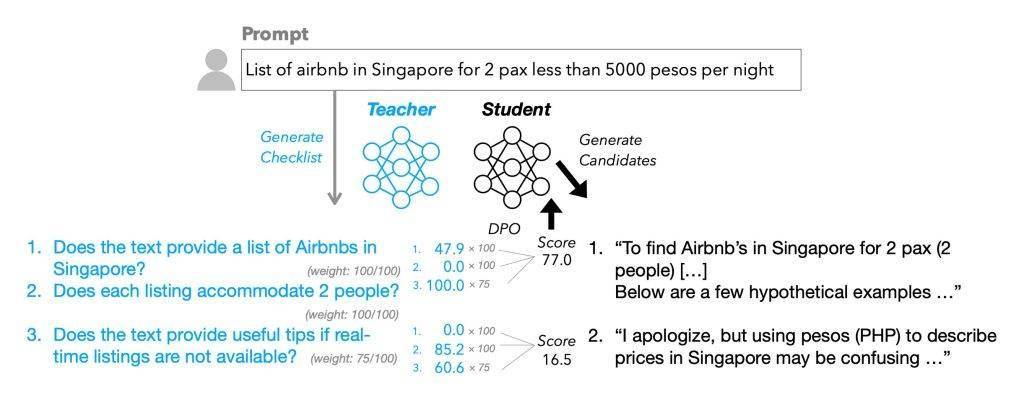

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





