|
|
爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
IT之家 3 月 27 日消息,美团今日发布原生多模态大模型 LongCat-Next,将图像、语音与文本统一映射为同源的离散 Token,使模型从学习连续空间的映射,转向学习离散 ID 之间的关系结构,并通过纯粹的下一个 Token 预测(Next Token Prediction, NTP)范式,以一种统一的方式建模各种物理信号。
美团还宣布把研究思路的核心 —— LongCat-Next 模型和它的离散分词器全部开源,希望更多开发者能基于它,构建真正能感知、理解并作用于真实世界的 AI。
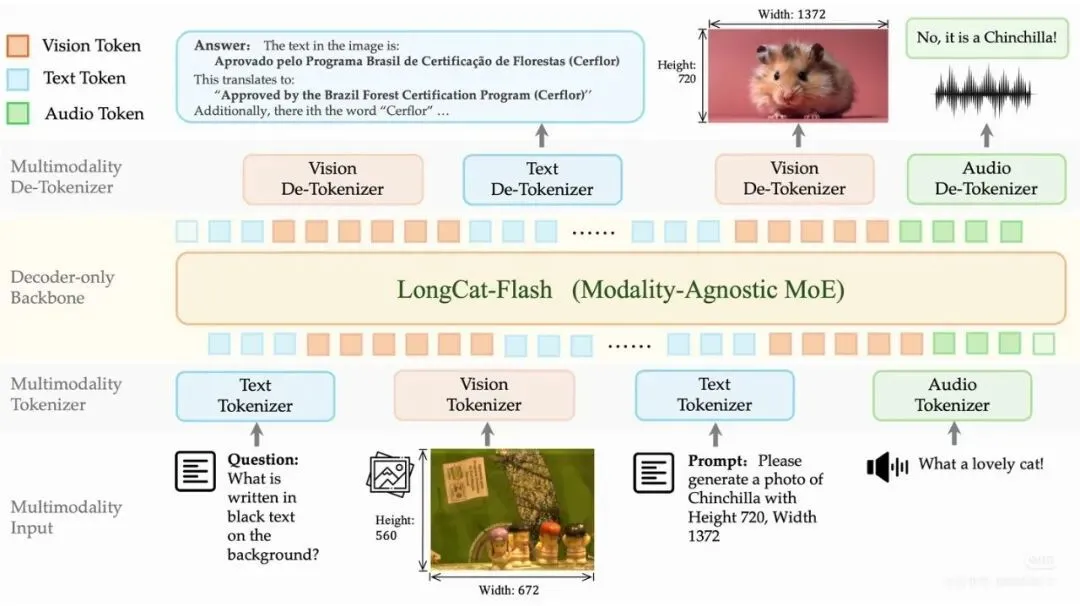
美团构建了 DiNA(Discrete Native Autoregressive)离散原生自回归架构。其核心就是将所有模态统一为离散 Token,并用同一个自回归模型进行建模。DiNA 打破了模态间的隔阂。它通过极简的下一 Token 预测(NTP)范式,将图像、声音和文字统一转化为同源的离散 Token。
简单而言,美团把文字、图像、语音都变成同一种东西 —— 离散 Token。无论读文字、看图片还是听声音,对 AI 来说都是同一件事:预测下一个 Token 是什么。
这种统一设计,让模型在训练时更稳定,部署时更轻量。美团用 LongCat-Flash-Lite MoE(68.5B 总参数,3B 激活参数)作为基座,在这个框架基础上训练了 LongCat-Next。
实验表明,DiNA 的 MoE 路由在训练中逐渐出现模态专精化,激活专家数量相比纯语言设置有所增加,模型正在用更大容量支撑能力扩展。
▲ LongCat-Next 架构概览,该架构基于 DiNA 范式设计
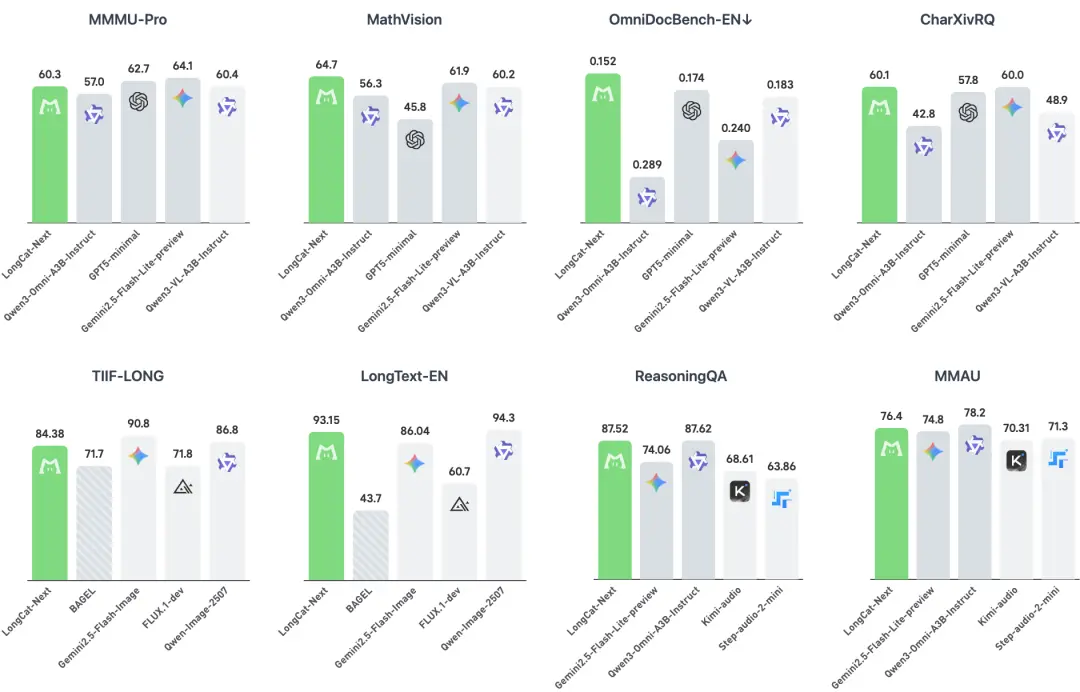
根据美团官方测试,LongCat-Next 在视觉理解、图像生成、音频、智能体等多个维度上,以一套离散原生框架展现出与多模专用模型相当甚至领先的性能。
LongCat-Next 在 OmniDocBench(学术论文、财报、行政表格)上的表现(0.152 / 0.226)不仅超越 Qwen3-Omni,还超过了专用视觉模型 Qwen3-VL。
消融实验对比中,LongCat-Next 统一模型的理解损失仅比纯理解模型高 0.006,而生成损失比纯生成模型低 0.02。在图像生成上,LongCat-Next 在 LongText-Bench(英文 93.15);在图像理解上,MathVista(83.1)达到领先水平。
在纯文本任务上,LongCat-Next 的 MMLU-Pro(77.02)和 C-Eval(86.80)表现领先,证明原生多模态训练未削弱语言核心能力。在工具调用上,τ²-Bench 零售场景(73.68)大幅领先 Qwen3-Next-80B-A3B-Instruct(57.3);在代码能力上,SWE-Bench(43.0)超越同类模型。
在音频领域,TTS 任务上,SeedTTS 的中文和英文 WER 分别低至 1.90 和 1.89;音频理解上,MMAU(76.40)、TUT2017(43.09)均达到先进水平。更重要的是,模型支持低延迟的并行文本语音生成与可定制的语音克隆,让语音交互更自然、更个性化。
|
|



 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2026-3-27 14:42:15
发表于 2026-3-27 14:42:15

 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶





