爱科技、爱创意、爱折腾、爱极致,我们都是技术控
您需要 登录 才可以下载或查看,没有账号?立即注册


x
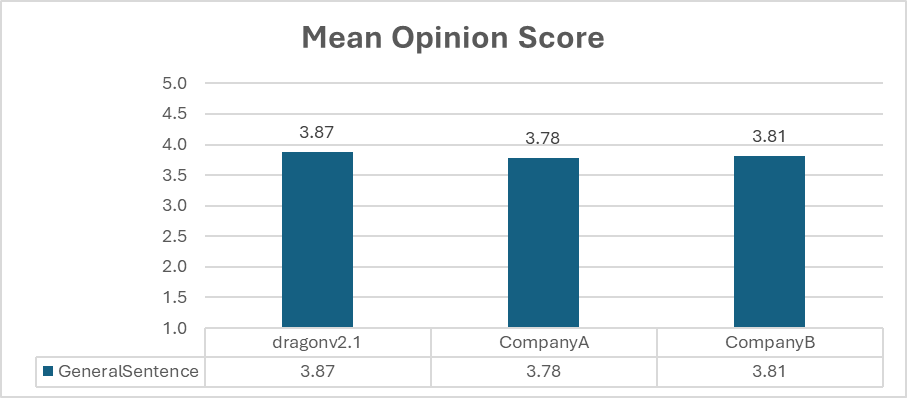
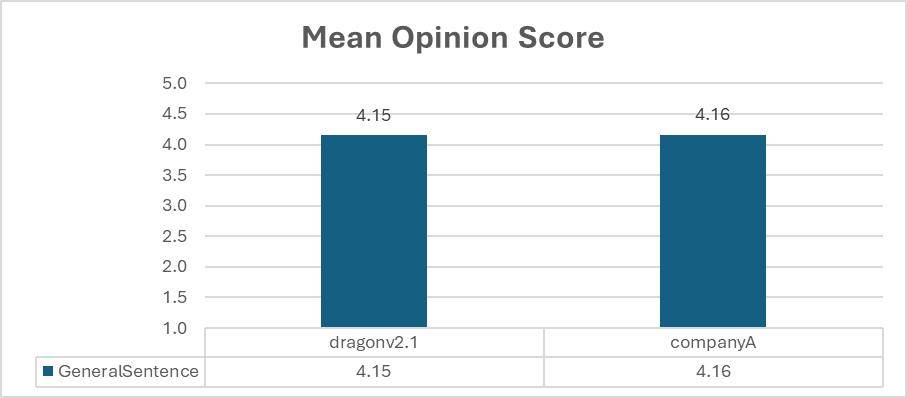
科技媒体 NeoWin 今天(7 月 31 日)发布博文,报道称微软推出了 DragonV2.1Neural 零次学习(Zero-Shot Learning)模型,仅凭少量数据就能创建更加自然、表现力强的声音,并支持超过 100 种语言。 IT之家援引博文介绍,这是一种零次学习的文本到语音(TTS)模型,承诺提供更加自然和富有表现力的声音,并提高了发音的准确性以及增强了可控性。 新模型仅需几秒钟的语音样本即可合成超过 100 种语言的语音。相比之下,之前的 DragonV1 模型在处理专有名词时存在发音问题。DragonV2.1 模型可以应用于多种不同场景,包括定制聊天机器人声音和为视频内容跨多语言配音。 微软表示,DragonV2.1 提高发音准确性,与 DragonV1 相比,该模型单词错误率(WER)平均降低了 12.8%。 该模型还提升了声音的自然度,用户使用此模型时,可以利用 SSML 音素标签和自定义词典对发音和口音进行细致控制。为了帮助用户入门,微软构建了 Andrew、Ava 和 Brian 等多个声音档案,供用户测试。
| 


 IP归属地
IP归属地 雷达卡
雷达卡 发表于 2025-7-31 21:42:52
发表于 2025-7-31 21:42:52
 提帖卡
提帖卡 置顶卡
置顶卡 锁帖卡
锁帖卡 解锁卡
解锁卡 显目卡
显目卡 千斤顶
千斤顶